Hand Pose Recognition With Microsoft Kinect and CogniMem V1KU
Microsoft has created an incredible device with the Micorosoft Kinect. Microsoft’s SDK is able to identify and track the skeletons of players in the frame. However, it does not provide any information about the position of the player’s fingers.
By training CogniMem’s CM1K pattern recognition accelerator on many examples, the chip is able to recognize distinct hand poses in the depth data from the Kinect sensor.
We’ve demoed this technology by creating a utility which maps your hand movement to the cursor position on a Windows PC, and which allows you to grab objects on the screen by simply closing your fist. With this simple gesture, you can play games like Angry Birds or World of Goo, or interact with applications like Windows Media Center.
Below are some videos of the demo in action.
Step 1: Isolating the Hand
 Before attempting to recognize the player’s hand, we want to filter out the background so that we’re only looking at what we care about–the shape of the player’s hand.
Before attempting to recognize the player’s hand, we want to filter out the background so that we’re only looking at what we care about–the shape of the player’s hand.
The Kinect’s depth sensor and the Microsoft Kinect for Windows SDK make this task fairly simple. The skeleton tracking information provides a pixel coordinate for the location of the hand in the depth frame. The SDK also performs the math for you to map every pixel in the depth frame to a 3D coordinate in space, with dimensions in meters.
Within a square region around the hand, we simply filter out every depth frame pixel which is farther than 150mm (about 6 inches) from the point in space identified as the hand. We’re effectively cutting out a sphere in space around the player’s hand. This means that we’ll be able to isolate the player’s hand even when it’s front of their chest (as long as they keep it at least 6 inches away).
##
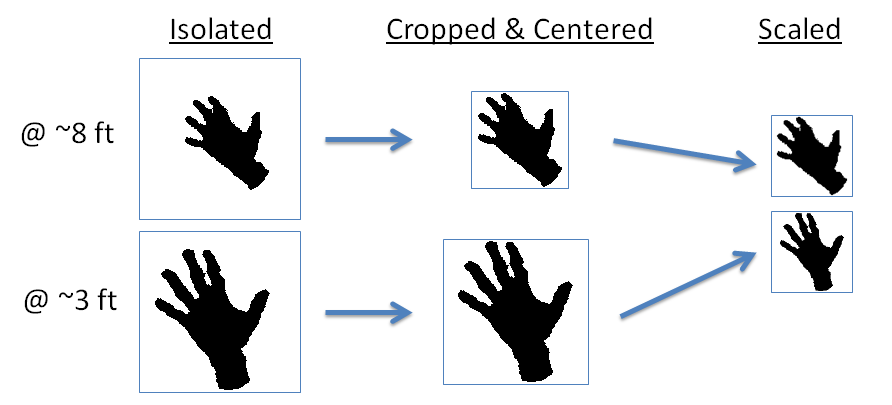
Step 2: Normalization
To simplify the recognition, we want to do whatever we can to make the hand images look as consistent as possible.
The player’s hand will appear larger or smaller in the depth frame depending on how far they are from the sensor. To account for this, we center the hand within the square region and crop in as much as possible, while still keeping the region square. Then, we scale the image down to a common size (16x16 pixels, or 256 bytes).
This ensures that all of the hand cutouts we look at will be roughly the same size before we attempt to classify them.
Step 3: Classification
The classification algorithm employed by CogniMem’s CM1K is easy to understand, apply, and debug, which makes it great to work with as a developer. It’s primary drawback is that it is brute force and does not scale well on a traditional CPU. However, the CM1K is a custom ASIC which implements the algorithm in a fully parallel and scalable way, making the approach feasible.
Essentially, the CM1K stores a collection of models or prototypes, up to 1024 of them per chip. Each model in the chip is a processing element with 256 bytes of memory to store the model.
The chip is trained on a large collection (currently over 60,000 images) of hands, and its training algorithm chooses which training examples it needs to store as models in order to correctly classify every single training input.
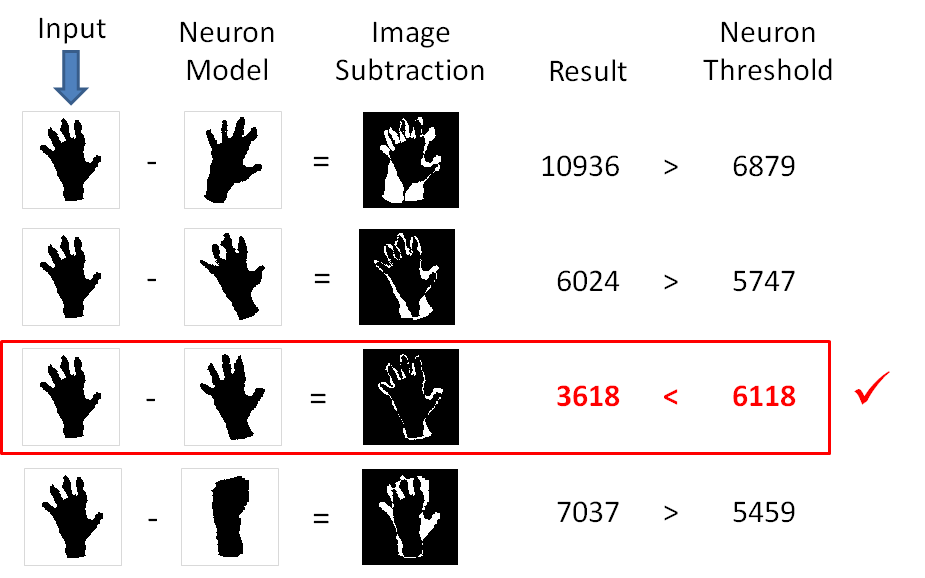
When a hand image is broadcast to the chip, each processing element compares the input to its model and computes a distance value (using sum of absolute differences, i.e. image subtraction). Each processing element also stores the category associated with its model, and a threshold value which has been set by the training algorithm. If the distance between a model and an input is less than the model’s threshold, it is considered a match.
The chip employs a patented search-and-sort technique which is able to return the closest matching model in a fixed amount of time. The hand is then classified as belonging to the category of that closest-matching model.
Conclusion
Through extensive training, the hand classification has been made robust enough that CogniMem has been able to use this as a demo at conferences and trade shows which anyone is free to try.
A notable strength of the classification algorithm is that if it ever misclassifies a players hand, it only needs to be trained on that hand in order to correct the mistake. This makes the machine learning approach much easier to achieve robust behavior than with a complex rules-based approach, for example.
There are some limitations to the demo as a whole:
-
It relies on Microsoft’s Kinect SDK for the location of the hand. The SDK is generally very reliable in locating the player’s hand, but performs poorly when the player stretches their hand far in any direction. The hand joint starts to drift down the players arm towards their elbow.
-
Large shirt cuffs can interfere with the recognition of the hand.
-
The Kinect’s depth sensor is considered to not have enough resolution to make out detail in a child’s hand. This is something we haven’t explored much, but we’ve heard that this was an important factor in Microsoft’s decision to not support hand recognition with the current generation Kinect.
Our hand recognition demo has been featured on a number of news sites:
-
http://hackaday.com/2012/07/17/finger-recognition-on-the-kinect/#more-79879
-
http://www.kinecthacks.net/kinect-finger-recognition-for-games/#comments
-
http://channel9.msdn.com/coding4fun/kinect/CogniMem-adds-pattern-recognition-to-the-Kinec
Finally, if you would like to try our hand recognition technology, a demo is available with the purchase of a V1KU development system. Visit the following page to submit inquiries: http://www.cognimem.com/products/product-inquiry/index.html