Colab GPUs Features & Pricing
Updated March 2026
This post has become a popular resource for understanding the Colab GPU ecosystem, and especially with the recent addition of the H100 and G4 options, I think it’s long overdue for an update.
I originally put this together while researching the topic of fine-tuning Large Language Models (LLMs) on a single GPU in Colab (a challenging feat!), comparing both the free (Tesla T4) and paid options. The goal was to assemble a table to make better sense of all the GPU choices–and it’s only gotten more interesting since!
By Chris McCormick
Contents
- Contents
- S1. Colab’s Value
- S2. Pricing Approach
- S3. Cost Per GPU
- S4. GPU Timeline
- S5. Performance & Features
- S6. Conclusion
- Appendix
S1. Colab’s Value
Colab used to be an insane, completely free service to the research community, where you could get free access to high end GPUs. Even when the Colab Pro subscription was added, I think you were still getting below-cost access.
I suspect that Stable Diffusion (the open source art generation model) may be what killed this… People built GUI tools on top of Colab that anyone could use to generate AI art for free, and suddenly a service meant for students and researchers had a much larger user base.
Today, I think Colab charges an amount more in line with the market rate for access to the GPUs.
The T4 is still free, though, and students, hobbyists, and low-income learners all over the world can still get hands-on with AI code that requires powerful GPUs to run. Thanks Google!
And for those willing and able to pay for some GPU time, I think the simplicity of working in Colab (and the simplicity of their payment approach) still make it a great choice for my purposes.
S2. Pricing Approach
The actual hourly cost of the different GPUs isn’t presented clearly (that I’ve found), so you have to work it out through a little experimentation–part of why I created this post!
Compute Units
First off, you pay for GPU time using the “compute units” in your account.
These cost $\frac{\text{\$10}}{\text{100 units}}$, or $\frac{\text{\$0.10}}{\text{unit}}$
The only way to get units is to pay $10 for 100 of them–pretty simple. There’s no bulk discount.
You can see their pricing plans and sign up here.
You can just pay as you go, or you can start a monthly subscription to Colab Pro / Pro+ and get a few more bells and whistles. 🤷♂️
Your Units Balance & the “Usage Rate”
The way to see how many units you still have left, and how much your current session is costing, is to click on the dropdown arrow in the upper right and select “View resources”
This will pop open a sidebar that shows your balance and current useage.
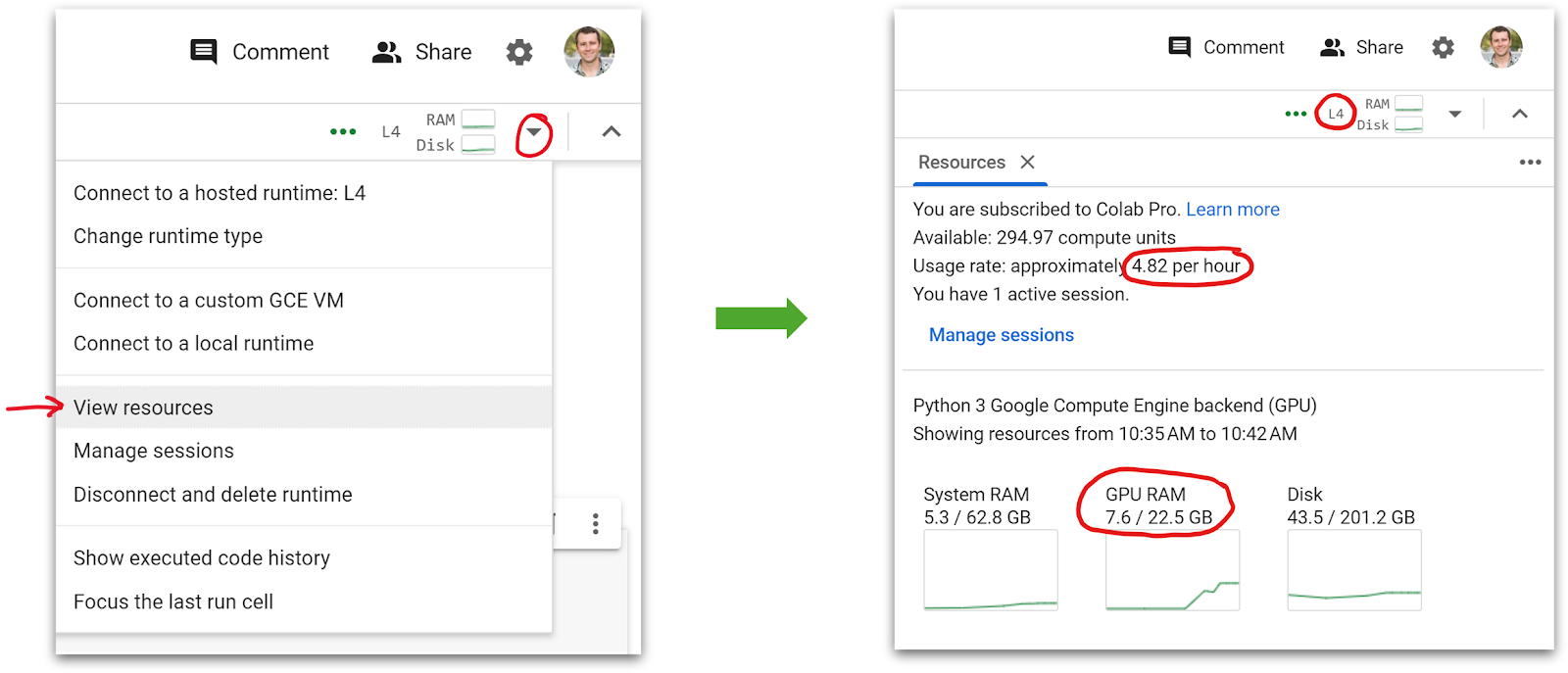
Side note: It hadn’t occurred to me before that this sidebar is a good place to check out your GPU memory useage while your code is running. (I usually print it out in my Notebooks with some clunky code, but that doesn’t let you see it mid-run!)
Tip: Colab Pro also gives you the ability to open a terminal (from the file browser on the left). You can run watch nvidia-smi there to get a live, auto-refreshing view of GPU utilization and memory–it can offer some more insight than the sidebar alone!
S3. Cost Per GPU
I’m sure pricing will change over time, it does seem to fluctuate a little (perhaps it’s based partly on current demand?) and I’m not sure how much your location factors in.
Despite all that, it still seems worth sharing some hard numbers to serve as rough estimates. Here’s what I’m seeing as of March 2026, in southern California.
Because a unit costs 1/10th of a dollar, you can easily calculate the price by shifting the decimal point one place to the left.
The fourth column shows you how much time you’ll get (in hours:minutes) for your $10.
| GPU | Units/hr | $/hr | Time (h:m) | Date Checked |
|---|---|---|---|---|
| T4 | 1.19 | $0.12 | 84:02 | 2026-03-10 |
| L4 | 1.71 | $0.17 | 58:29 | 2026-03-10 |
| A100 (40GB) | 5.40 | $0.54 | 18:31 | 2026-03-10 |
| A100 (80GB) | 7.52 | $0.75 | 13:18 | 2026-03-10 |
| G4 | 8.71 | $0.87 | 11:29 | 2026-03-10 |
| H100 | ? | ? | ? | – |
A couple notes on these:
- The A100 now comes in both a 40GB and 80GB version on Colab–you choose between them with the “High RAM” slider in the GPU settings.
- The “G4” is actually an NVIDIA RTX PRO 6000 (Blackwell architecture) with a whopping ~96 GB of VRAM. More on that below.
- I haven’t been able to get my hands on an H100 yet to check the rate, but it’s now listed as an option!
S4. GPU Timeline
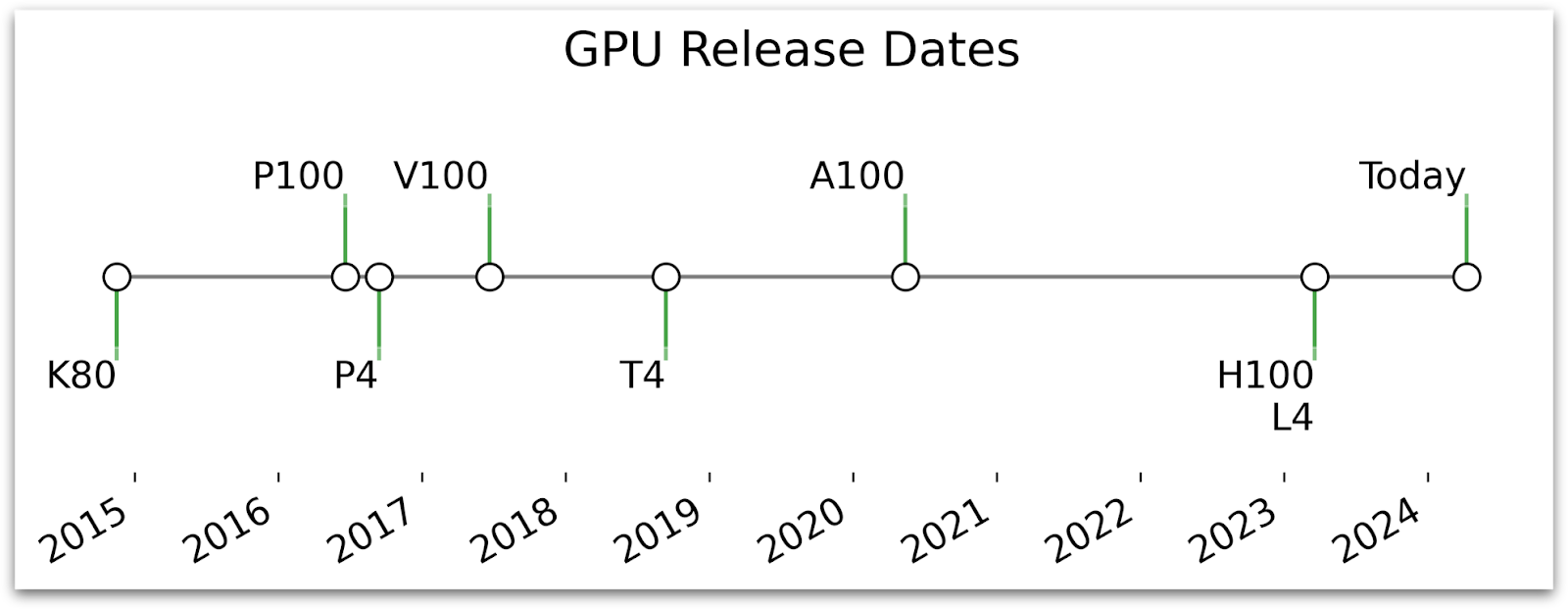
The Wikipedia page for Tesla cards here has a comprehensive table that covers the many variants of these cards, but I wanted to focus in on what’s available in Colab.
Note that the “Launch Date” is tricky–I tried to capture when they actually started shipping / became available in the cloud as opposed to when they were announced.
| GPU Model | Architecture | Launch Date | VRAM | Website |
|---|---|---|---|---|
| T4 | Turing | 9/13/18 | 15 GB | Details |
| A100 | Ampere | 5/14/20 | 40 / 80 GB | Details |
| L4 | Ada Lovelace | 3/21/23 | 22.5 GB | Details |
| H100 | Hopper | 3/21/23 | 80 GB | Details |
| G4 (RTX PRO 6000) | Blackwell | ~2025 | 96 GB | Details |
Some notes:
- The V100 (Volta architecture, 2017) used to be on Colab but has been removed.
- The A100 now comes in both 40GB and 80GB variants on Colab–use the “High RAM” slider to select the 80GB version.
- The
HopperandAda Lovelacearchitectures are the same generation, but Hopper was designed specifically for AI and is the successor to the A100. The H100 brings FP8 support and FlashAttention 3. - The G4 is listed as “G4” in Colab’s GPU menu, but
nvidia-smireveals it’s actually an NVIDIA RTX PRO 6000 on the Blackwell architecture–with a massive ~96 GB of VRAM! - The T4 is marketed as 16GB, but only 15GB is useable because 1GB is used for the card’s “error code correction” (ECC) function (from here).
What’s ECC? While Neural Networks are fuzzy and don’t require strict precision, other types of scientific computing require high precision, motivating 64-bit floats and ECC, which protects against occassional bit flips by–not kidding–cosmic rays. Ok, that’s only one of the causes, but still!
S5. Performance & Features
5.1. Speed
Speed comparisons on GPUs can be tricky–they depend on your use case. I’ll give you some anecdotal numbers, though, based on my current project where I’m trying to fine-tune an LLM on a single GPU.
For my application, I want a maximum sequence length of 1,024 and a batch size of 4. However, there is not enough memory on the T4 to run this, unless I employ some tricks which sacrifice training speed (namely, gradient checkpointing).
At Reduced Settings
For the sake of a straight comparison, I can reduce the sequence length to 512 and the batch size to 1 (and no gradient checkpointing or accumulation).
With these reduced settings, it looks like 500 training steps will take roughly:
- T4 = 12 min
- L4 = 5.5 min (~2.2x faster than T4)
- A100 = 2 min (~6x faster than T4)
At Desired Settings
But those aren’t the actual settings that I want to run with! I want a sequence length of 1,024 and an effective training batch size of 4.
The performance difference gets larger in this context, with the A100 becoming 13 times faster than the T4!
| GPU | Seq Len | Grad Check | Batch Size | Accumulation Steps | Memory Use | Time | Speed vs. T4 |
|---|---|---|---|---|---|---|---|
| T4 | 1024 | True | 1 | 4 | 7.0GB | ~2h 10min | 1x |
| L4 | 1024 | False | 1 | 4 | 17.5GB | ~47min | 2.8x |
| A100 | 1024 | False | 2 | 2 | 28.1 GB | ~10min | 13x |
Note how the memory usage compares to the memory of each GPU. To avoid using gradient checkpointing, I needed 17.5GB, which is more than the T4s 15GB. In order to use a larger batch size (and take better advantage of the GPU’s parallelism), I needed 28.1 GB of memory, which is larger than the L4’s 22.5GB.
Memory is key!
TeraFLOPS
NVIDIA likes to report teraflops as the metric for GPU performance, but my understanding is that these are measured on a simple matrix multiplication that fully utilizes the GPU, and you’re not likely to see the same performance if you tried calculating the FLOPs you’re getting in your application.
However, based on the above, they do appear to be a reasonable measure for comparing the relative speed of the GPUs:
| GPU | teraFLOPS | Precision | Mult. |
|---|---|---|---|
| T4 | 65 | FP16 | - |
| L4 | 121 | FP16 | 1.9x |
| A100 | 312 | FP16 | 4.8x |
| H100 | 990 | FP16 | 15.2x |
(I was suspicious that maybe the performance gains wouldn’t be as large as the teraFLOPS would suggest, but I’m actually seeing larger gains).
I don’t have benchmarks for the H100 or G4 yet for this particular use case, but the teraFLOPS numbers give a sense of the leap–the H100 is in a different league!
Cost Effectiveness
It seems that if your task fits within the T4’s memory, it may actually be the lowest cost for doing a training run. But if the extra memory helps, then the A100 can actually be cheaper.
That’s only considering the hardware cost, though–saving engineering time and being able to iterate faster is a huge benefit!
5.2. FlashAttention on the T4
FlashAttention is a clever rewrite of the attention calculation GPU code which results in a significant improvement in speed and memory use. In my experience, it provides the most benefit at longer sequence lengths, such as 1k and up.
“Squared Dot Product Attention” (sdpa) has been implemented as of Jan 2024 in PyTorch v2.2, and If I understand correctly it’s the more generic name for the key contribution of FlashAttention.
In my experiments SDPA seems to provide roughly the same improvement as FlashAttention v2, and it’s the default choice in HuggingFace.
On The T4
The reason I bring it up is that the original FlashAttention v2 isn’t implemented for the T4, but this doesn’t seem to matter since SDPA is supported on the T4.
More specifically:
You select your attention implementation in HuggingFace when loading your model using the attn_implementation parameter of the from_pretrained function.
It gives you three choices:
- “eager” - The simple/original approach
- “flash_attention_2” - The original implementation by Dao.
- “sdpa” - From PyTorch, selected by default
If you try selecting “flash_attention_2” on the T4, you’ll get an error. But again, I don’t think this matters–just stick with “sdpa” (the default).
FlashAttention 3 on the H100
The H100 (Hopper architecture) supports FlashAttention 3, the latest version, which takes advantage of Hopper-specific hardware features for even better performance. If you’re lucky enough to land an H100 in Colab, you’re getting the best attention implementation available.
Research Notes
-
I had a really hard time locating the docs for this! I finally figured out that
from_pretrainedcomes from thePreTrainedModelclass, and theattn_implementationparameter is documented here. -
According to the author / GitHub repo here:
-
“Ampere, Ada, or Hopper GPUs (e.g., A100, RTX 3090, RTX 4090, H100). Support for Turing GPUs (T4, RTX 2080) is coming soon, please use FlashAttention 1.x for Turing GPUs for now.”
-
5.3. No bfloat16 on the T4
What’s bfloat16?
“Brain Floating Point” or “bfloat16”, (named because it was developed at Google Brain) is a data type with advantages for neural network training over float16. It has to be implemented in hardware, and is supported by all the GPUs on Colab except the T4. (The A100, L4, H100, and G4 all support it.)
Compared to float16 it’s able to represent much tinier numbers (all the way down to about $1.2 \times 10^{−38}$) and much bigger numbers (all the way up to about \( 3.4 \times 10^{38} \)).
Neural networks, particularly deep ones, can have problems with gradients getting very large or very small, and bfloat16 has much less rounding error than float16 in these domains.
The trade-off is that bfloat16 has more rounding error inside the range of values that float16 can represent, \( 6 \times 10^{-8} \) to \( 64\text{K} \), but neural networks are apparently less impacted by reduced precision in that range.
Side Note: I thought it was interesting to learn that
bfloat16uses the same number of bits for the exponent asfloat32, and is able to represent the same range of values asfloat32, just with less precision.
Why does it matter in practice?
To try to understand this, I asked ChatGPT to tell me a story about the day in the life of a researcher impacted by this issue.
The key takeaways were that numerical instability resulted in:
“The loss function fluctuated wildly from one epoch to the next, and the performance metrics exhibit erratic behavior”
And that by switching to bfloat16:
“The loss function converges more smoothly, and the model’s performance becomes more consistent across different runs.”
Clearly, you’re not doomed to failure by using float16, and you may or may not encounter these issues based on other factors (ChatGPT did have a little more to say about why you may or may not encounter this–you can read my discussion with ChatGPT about it here). So I really have no idea how “make or break” this feature is!
I’d love to be able to share a real anecdote around this. Maybe I’ll try running with and without it for a project or two and see if I notice any difference. 🤷♂️
I hate flags…
There is one datapoint I can share from experience on this topic–it’s a pain in the butt to switch between float16 and bfloat16 depending on which GPU you’re using.
For fine-tuning LLMs, this datatype needs to be specified in several different spots, and I’m really resistant to mucking up my tutorial code with “If GPU == T4” checks!
FP8
The H100 additionally supports FP8 operations. FP8 is not a normal data type, however–you can’t simply cast your value to an 8-bit float and expect anything to work. It requires multiplying the values by custom-tuned scaling factors.
It’s its own interesting topic that I’ll have to cover another time.
S6. Conclusion
Lower-end Colab GPUs are a great option for getting onto a GPU with minimal overhead to test your code.
Once I’m ready for a longer training run or batch of runs, I generally go for whatever will give me the fastest turnaround for experimenting.
Happy training!
Appendix
Acknowledgements
Thanks Chris Perry (Colab Product Lead) for looking over the post!
📚 Cite
Please use the following BibTex for citing this article.
@misc{mccormick2024colabgpus,
title={Colab GPUs Features and Pricing},
author={McCormick, C},
year={2024},
url={https://mccormickml.com/2024/04/23/colab-gpus-features-and-pricing/}
}
Or
McCormick, C (2024). Colab GPUs Features and Pricing [Blog post]. Retrieved from https://mccormickml.com/2024/04/23/colab-gpus-features-and-pricing/