K-Fold Cross-Validation, With MATLAB Code
In order to build an effective machine learning solution, you will need the proper analytical tools for evaluating the performance of your system. Cross-validation is one of the most important tools, as it gives you an honest assessment of the true accuracy of your system.
Also, if there are parameters in your system that you have to select manually, you can often choose the best value analytically by trying out different values and comparing the resulting cross-validation accuracy.
The Need For A Validation Set
In all machine learning algorithms, the goal of the learning algorithm is to build a model which makes accurate predictions on the training set. Because of this, machine learning classifiers tend to perform very well on the data they were trained on (provided they have the power to fit the data well).
Training set accuracy is not a good indication, however, of how well the classifier will perform when classifying new data outside of the training set. We need some other measure to give us an idea of how accurate our classifier will be when we deploy it.
The cross-validation process provides a much more accurate picture of your system’s true accuracy. In cross-validation, we divide our data into a large training set and a smaller validation set, then train on the training set and use the validation set to measure our accuracy.
To be a good measure of accuracy, we want the validation data to be representative of the range of inputs the classifier is likely to encounter. This has two important implications.
The first is that it is generally better to randomly select the validation examples from our existing collection of data, rather than to go out and gather a separate set of examples specifically for validation (which is how I used to do it! :) ). You want the validation set to be diverse.
The other implication is that the accuracy and usefulness of the cross-validation process depends on having a data set which is, in the first place, representative of the range of possible inputs we expect to see. For example, if we are working on a vision application and have only gathered samples under a very specific set of lighting conditions, cross-validation won’t help us determine how well the system will perform under different lighting conditions.
There are different approaches to selecting the training and validation sets. One simple approach is to randomly select, e.g., 80% of your existing data to use for training and 20% to use for validation. There is some risk, though, that you will be ‘unlucky’ in your selection of validation points, and the validation set will contain a disproportionate number of difficult or obscure examples. To combat this, you can perform k-fold cross validation.
K-Fold Cross-Validation
In this procedure, you randomly sort your data, then divide your data into k folds. A common value of k is 10, so in that case you would divide your data into ten parts.
You’ll then run ‘k’ rounds of cross-validation. In each round, you use one of the folds for validation, and the remaining folds for training. After training your classifier, you measure its accuracy on the validation data. Average the accuracy over the k rounds to get a final cross-validation accuracy.
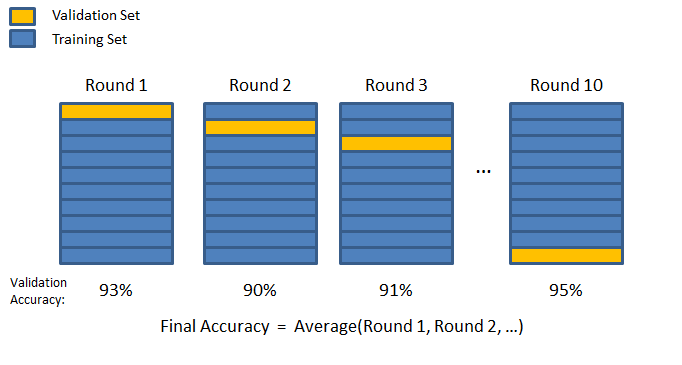
Figure: 10-fold cross-validation. The data set is divided into 10 portions or “folds”. One fold is designated as the validation set, while the remaining nine folds are all combined and used for training. The validation accuracy is computed for each of the ten validation sets, and averaged to get a final cross-validation accuracy. The accuracy numbers shown here are just for illustration.
MATLAB Code
I’ve written some functions which can help you divide your data set into training and validation sets for n-fold cross-validation.
You should have all of your data points in a matrix X where each row is a separate data point. You should also have a column vector y containing the category (or class label) for each of the corresponding data points.
You will also need to define a column vector ‘categories’ which just lists the class label values you are using. I require this so that the code doesn’t make any assumptions about the values you are using for your class labels. You could use ‘0’ as one of the categories if you want, for example, and the values don’t have to be contiguous.
Here are links to each of the functions, with a short description of what each does. There is also a simple example usage at the end.
getVecsPerCat.m - Counts the number of vectors belonging to each category.
computeFoldSizes.m - Pre-compute the size of each of the n folds for each category. The number of folds might not divide evenly into the number of vectors, so this function handles distributing the remainder across the folds.
randSortAndGroup.m - Sorts the vectors by category, and randomizes the order of the vectors within each category.
getFoldVectors.m - For the specified round of cross-validation, selects X_train, y_train (the vectors to use for training, with their associated categories) and X_val, y_val (the vectors to use for validation, with their associated categories).
After calling getFoldVectors, it’s up to you to perform the actual training, and compute your validation accuracy on the validation vectors. Below is some sample code for using the above functions, but note that it ommits the actual training and validation steps.
% List out the category values in use.
categories = [0; 1];
% Get the number of vectors belonging to each category.
vecsPerCat = getVecsPerCat(X, y, categories);
% Compute the fold sizes for each category.
foldSizes = computeFoldSizes(vecsPerCat, 10);
% Randomly sort the vectors in X, then organize them by category.
[X_sorted, y_sorted] = randSortAndGroup(X, y, categories);
% For each round of cross-validation...
for (roundNumber = 1 : 10)
% Select the vectors to use for training and cross validation.
[X_train, y_train, X_val, y_val] = getFoldVectors(X_sorted, y_sorted, categories, vecsPerCat, foldSizes, roundNumber);
% Train the classifier on the training set, X_train y_train
% .....................
% Measure the classification accuracy on the validation set.
% .....................
end