What is an L2-SVM?
While reading through various deep learning research papers, I’ve come across the term “L2-SVM” a couple times.
For example:
-
“In our experiments we use (L2) SVM classification.” - _An Analysis of Single-Layer Networks in Unsupervised Feature Learning, _Coates et. al, 2011.
-
“Our experiments are primarily based on L2SVM objectives” - _Deeply-Supervised Nets, _Lee et. al, 2014
I have some familiarity with Support Vector Machines, but not enough to understand what’s meant specifically by an “L2-SVM”.
I found a quick answer though, in the paper Comparison of L1 and L2 Support Vector Machines, Koshiba et al, 2003.
Support vector machines with linear sum of slack variables, which are commonly used, are called L1-SVMs, and SVMs with the square sum of slack variables are called L2-SVMs.
It’s really just a slight difference in the objective function used to optimize the SVM.
The objective for an L1-SVM is:
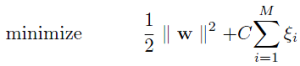
And for an L2-SVM:

The difference is in the regularization term, which is there to make the SVM less susceptible to outliers and improve its overall generalization.
So why use the L2 objective versus the L1?
The paper _Deep Learning Using Support Vector Machines, _Yichuan Tang, 2013 offers some insight:
L2-SVM is differentiable and imposes a bigger (quadratic vs. linear) loss for points which violate the margin.
If you want to dig deeper into the topic, that paper is probably a good bet.
All of these deep neural networks ultimately spit out a final feature vector representation of the input, which must then be classified (if classification is the task at hand). This is generally done using a simple linear classifier. The general impression that I’m getting from these various papers is that training the classifier using the L2-SVM objective function outperforms other methods such as L1-SVM or Softmax regression.
If you’re looking for some example MATLAB code, Adam Coates provides the code for his original CIFAR-10 benchmark implementation here:
http://www.cs.stanford.edu/~acoates/papers/kmeans_demo.tgz
and his code uses the L2-SVM objective to train the output classifier.