Continuing Pre-Training on Raw Text
This blog post builds upon a community notebook from Unsloth titled Mistral 7B Text Completion - Raw Text Training Full Example.
This blog post builds upon a community notebook from Unsloth titled Mistral 7B Text Completion - Raw Text Training Full Example.
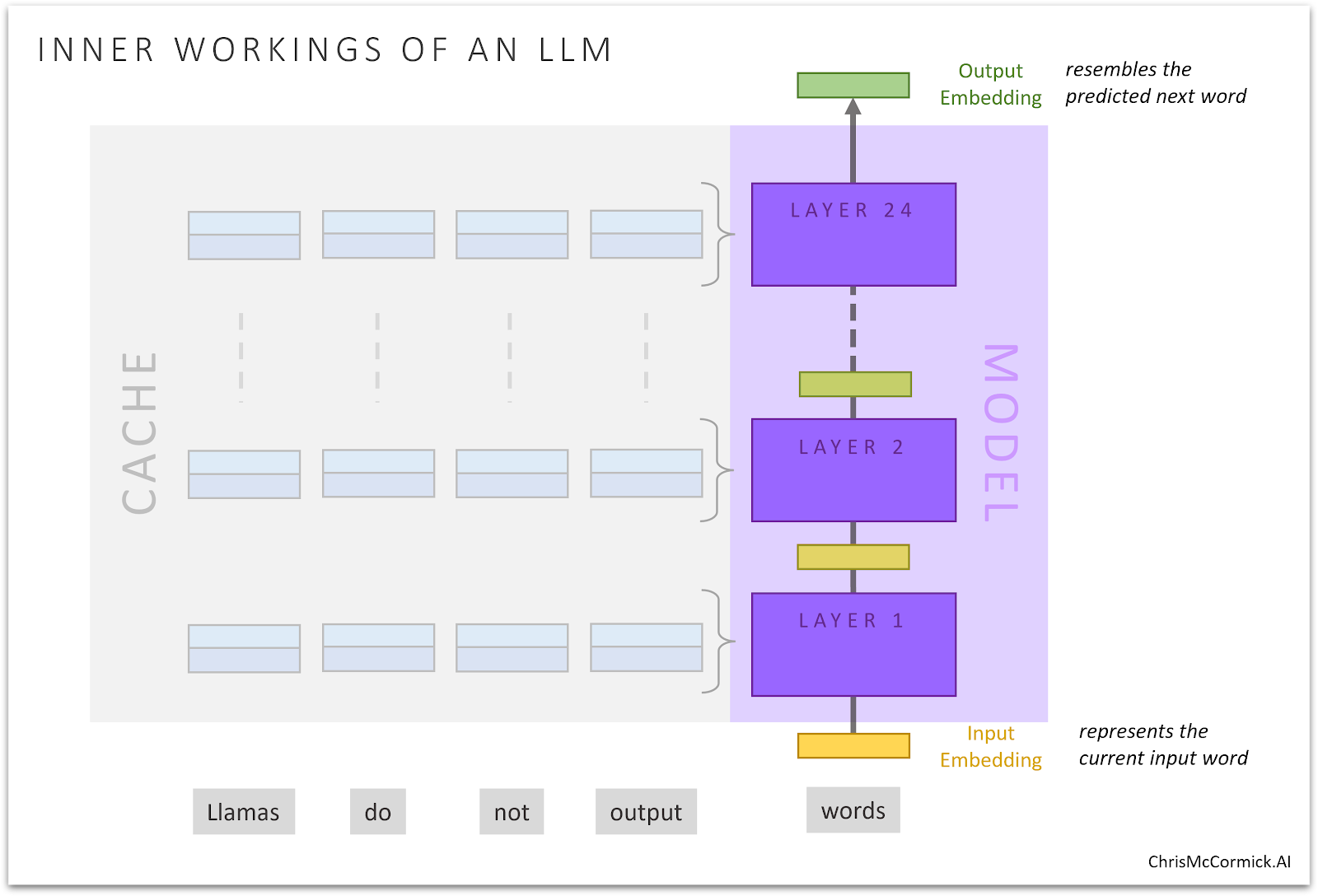
I’ve been curious to see just how well these enormous LLMs perform at traditional NLP tasks such as classifying text.

An in-depth tutorial on the algorithm and paper, including a pseudo-implementation in Python.
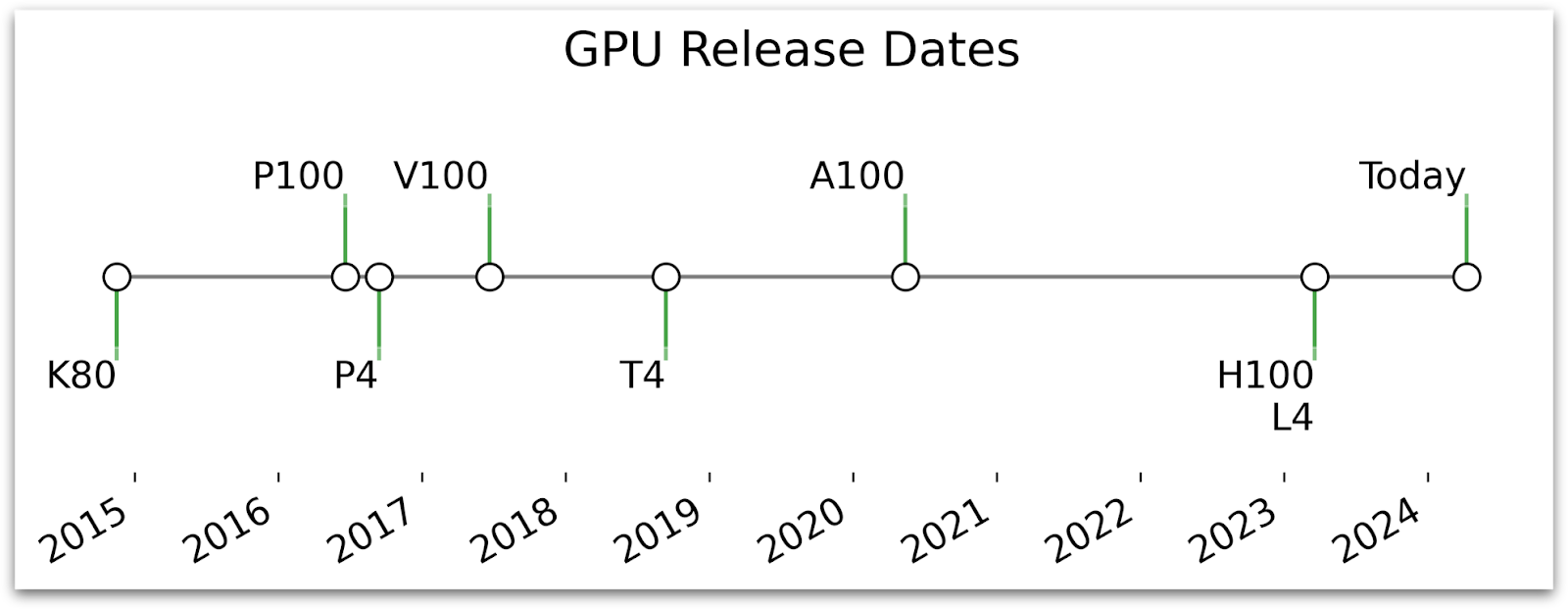
Recently I’ve been researching the topic of fine-tuning Large Language Models (LLMs) like GPT on a single GPU in Colab (a challenging feat!), comparing both the free (Tesla T4) and paid options.
![]()