XLNet Fine-Tuning Tutorial with PyTorch
By Chris McCormick and Nick Ryan
In this tutorial, I’ll show you how to finetune the pretrained XLNet model with the huggingface PyTorch library to quickly produce a classifier for text classification.
Introduction
(This post follows the previous post on finetuning BERT very closely, but uses the updated interface of the huggingface library (pytorch-transformers) and customizes the input for use in XLNet.)
This post is presented in two forms–as a blog post here and as a Colab notebook here. The content is identical in both, but:
- The blog post format may be easier to read, and includes a comments section for discussion.
- The Colab Notebook will allow you to run the code and inspect it as you read through.
What is XLNet?
XLNet is a method of pretraining language representations developed by CMU and Google researchers in mid-2019. XLNet was created to address what the authors saw as the shortcomings of the autoencoding method of pretraining used by BERT and other popular language models. We won’t get into the details of XLNet in this post, but the authors favored a custom autoregressive method. This pretraining method resulted in models that outperformed BERT on a range of NLP tasks and resulted in a new state of the art model.
Install and Import
Google Colab offers free GPUs and TPUs! Since we’ll be training a large neural network it’s best to take advantage of this (in this case we’ll attach a GPU), otherwise training will take a very long time.
A GPU can be added by going to the menu and selecting:
Edit -> Notebook Settings -> Add accelerator (GPU)
Then run the following cell to confirm that the GPU is detected.
import tensorflow as tf
device_name = tf.test.gpu_device_name()
if device_name != '/device:GPU:0':
raise SystemError('GPU device not found')
print('Found GPU at: {}'.format(device_name))
Found GPU at: /device:GPU:0
Next, let’s install the pytorch interface for XLNet by Hugging Face. (This library contains interfaces for other pretrained language models like OpenAI’s GPT, BERT, and GPT-2.) We’ve selected the pytorch interface because it strikes a nice balance between the high-level APIs (which are easy to use but don’t provide insight into how things work) and tensorflow code (which contains lots of details but often sidetracks us into lessons about tensorflow)
At the moment, the Hugging Face library seems to be the most widely accepted and powerful pytorch interface for working with transfer learning models. In addition to supporting a variety of different pre-trained language models (and future models to come - just a few short months after the publication of BERT and XLNet, both have been outperformed by new models!), the library also includes pre-built modifications of different models suited to your specific task. For example, in this tutorial we will use XLNetForSequenceClassification, but the library also includes model modifications designed for token classification, question answering, next sentence prediciton, etc. Using these pre-built classes simplifies the process of modifying transfer learning models for your purposes.
!pip install pytorch-transformers
import torch
from torch.utils.data import TensorDataset, DataLoader, RandomSampler, SequentialSampler
from keras.preprocessing.sequence import pad_sequences
from sklearn.model_selection import train_test_split
from pytorch_transformers import XLNetModel, XLNetTokenizer, XLNetForSequenceClassification
from pytorch_transformers import AdamW
from tqdm import tqdm, trange
import pandas as pd
import io
import numpy as np
import matplotlib.pyplot as plt
% matplotlib inline
Using TensorFlow backend.
In order for torch to use the GPU, we need to identify and specify the GPU as the device. Later, in our training loop, we will load data onto the device.
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
n_gpu = torch.cuda.device_count()
torch.cuda.get_device_name(0)
'Tesla T4'
Load Dataset
We’ll use The Corpus of Linguistic Acceptability (CoLA) dataset for single sentence classification. It’s a set of sentences labeled as grammatically correct or incorrect. The data is as follows:
Column 1: the code representing the source of the sentence.
Column 2: the acceptability judgment label (0=unacceptable, 1=acceptable).
Column 3: the acceptability judgment as originally notated by the author.
Column 4: the sentence.
Download the dataset from this link, extract, and move them to your local drive.
https://nyu-mll.github.io/CoLA/
Both tokenized and raw versions of the data are available. We will use the raw version because we need to use the XLNet tokenizer to break the text down into tokens and chunks that the model will recognize.
# Upload the train file from your local drive
from google.colab import files
uploaded = files.upload()
<input type="file" id="files-b062ce50-5098-494c-9fa0-58a7200a8b0e" name="files[]" multiple disabled />
<output id="result-b062ce50-5098-494c-9fa0-58a7200a8b0e">
Upload widget is only available when the cell has been executed in the
current browser session. Please rerun this cell to enable.
</output>
<script src="/nbextensions/google.colab/files.js"></script>
Saving in_domain_train.tsv to in_domain_train.tsv
df = pd.read_csv("in_domain_train.tsv", delimiter='\t', header=None, names=['sentence_source', 'label', 'label_notes', 'sentence'])
df.shape
(8551, 4)
df.sample(10)
| sentence_source | label | label_notes | sentence | |
|---|---|---|---|---|
| 7846 | ad03 | 1 | NaN | Gilgamesh should slowly be tickling the mandrake. |
| 5770 | c_13 | 1 | NaN | Marilyn Monroe is Norma Jeane Baker. |
| 6872 | m_02 | 1 | NaN | The Ethel we all know and love wishes to ask y... |
| 4130 | ks08 | 0 | * | After reading the pamphlet, Judy threw them in... |
| 5713 | c_13 | 1 | NaN | The cat put her catnip toy on the plastic mat. |
| 8193 | ad03 | 1 | NaN | Moya's football team loved her |
| 5768 | c_13 | 1 | NaN | Although he loves marshmallows, John is not a ... |
| 2849 | l-93 | 1 | NaN | Carol cut the bread with a knife. |
| 6983 | m_02 | 1 | NaN | Fiona may be here by 5 o'clock. |
| 3401 | l-93 | 0 | * | The thief chased. |
# Create sentence and label lists
sentences = df.sentence.values
We need to add special tokens (“[SEP]” and “[CLS]”) at the beginning and end of each sentence for XLNet to work properly.
For BERT, the special token pattern looks like this:
[CLS] + Sentence_A + [SEP] + Sentence_B + [SEP]
Whereas with XLNet the token pattern looks like this:
Sentence_A + [SEP] + Sentence_B + [SEP] + [CLS]
For single sentence inputs here, we just need to add [SEP] and [CLS] to the end:
sentences = [sentence + " [SEP] [CLS]" for sentence in sentences]
labels = df.label.values
Inputs
Next, import the XLNet tokenizer, used to convert our text into tokens that correspond to XLNet’s vocabulary.
tokenizer = XLNetTokenizer.from_pretrained('xlnet-base-cased', do_lower_case=True)
tokenized_texts = [tokenizer.tokenize(sent) for sent in sentences]
print ("Tokenize the first sentence:")
print (tokenized_texts[0])
100%|██████████| 798011/798011 [00:00<00:00, 860331.05B/s]
Tokenize the first sentence:
['▁our', '▁friends', '▁won', "'", 't', '▁buy', '▁this', '▁analysis', ',', '▁let', '▁alone', '▁the', '▁next', '▁one', '▁we', '▁propose', '.', '▁[', 's', 'ep', ']', '▁[', 'cl', 's', ']']
XLNet requires specifically formatted inputs. For each tokenized input sentence, we need to create:
- input ids: a sequence of integers identifying each input token to its index number in the XLNet tokenizer vocabulary
- segment mask: (optional) a sequence of 1s and 0s used to identify whether the input is one sentence or two sentences long. For one sentence inputs, this is simply a sequence of 0s. For two sentence inputs, there is a 0 for each token of the first sentence, followed by a 1 for each token of the second sentence
- attention mask: (optional) a sequence of 1s and 0s, with 1s for all input tokens and 0s for all padding tokens (we’ll detail this in the next paragraph)
- labels: a single value of 1 or 0. In our task 1 means “grammatical” and 0 means “ungrammatical”
Although we can have variable length input sentences, XLNet does requires our input arrays to be the same size. We address this by first choosing a maximum sentence length, and then padding and truncating our inputs until every input sequence is of the same length.
To “pad” our inputs in this context means that if a sentence is shorter than the maximum sentence length, we simply add 0s to the end of the sequence until it is the maximum sentence length.
If a sentence is longer than the maximum sentence length, then we simply truncate the end of the sequence, discarding anything that does not fit into our maximum sentence length.
We pad and truncate our sequences so that they all become of length MAX_LEN (“post” indicates that we want to pad and truncate at the end of the sequence, as opposed to the beginning) pad_sequences is a utility function that we’re borrowing from Keras. It simply handles the truncating and padding of Python lists.
# Set the maximum sequence length. The longest sequence in our training set is 47, but we'll leave room on the end anyway.
MAX_LEN = 128
# Use the XLNet tokenizer to convert the tokens to their index numbers in the XLNet vocabulary
input_ids = [tokenizer.convert_tokens_to_ids(x) for x in tokenized_texts]
# Pad our input tokens
input_ids = pad_sequences(input_ids, maxlen=MAX_LEN, dtype="long", truncating="post", padding="post")
Create the attention masks
# Create attention masks
attention_masks = []
# Create a mask of 1s for each token followed by 0s for padding
for seq in input_ids:
seq_mask = [float(i>0) for i in seq]
attention_masks.append(seq_mask)
# Use train_test_split to split our data into train and validation sets for training
train_inputs, validation_inputs, train_labels, validation_labels = train_test_split(input_ids, labels,
random_state=2018, test_size=0.1)
train_masks, validation_masks, _, _ = train_test_split(attention_masks, input_ids,
random_state=2018, test_size=0.1)
# Convert all of our data into torch tensors, the required datatype for our model
train_inputs = torch.tensor(train_inputs)
validation_inputs = torch.tensor(validation_inputs)
train_labels = torch.tensor(train_labels)
validation_labels = torch.tensor(validation_labels)
train_masks = torch.tensor(train_masks)
validation_masks = torch.tensor(validation_masks)
# Select a batch size for training. For fine-tuning with XLNet, the authors recommend a batch size of 32, 48, or 128. We will use 32 here to avoid memory issues.
batch_size = 32
# Create an iterator of our data with torch DataLoader. This helps save on memory during training because, unlike a for loop,
# with an iterator the entire dataset does not need to be loaded into memory
train_data = TensorDataset(train_inputs, train_masks, train_labels)
train_sampler = RandomSampler(train_data)
train_dataloader = DataLoader(train_data, sampler=train_sampler, batch_size=batch_size)
validation_data = TensorDataset(validation_inputs, validation_masks, validation_labels)
validation_sampler = SequentialSampler(validation_data)
validation_dataloader = DataLoader(validation_data, sampler=validation_sampler, batch_size=batch_size)
Train Model
Now that our input data is properly formatted, it’s time to fine tune the XLNet model.
For this task, we first want to modify the pre-trained model to give outputs for classification, and then we want to continue training the model on our dataset until that the entire model, end-to-end, is well-suited for our task. Thankfully, the huggingface pytorch implementation includes a set of interfaces designed for a variety of NLP tasks. Though these interfaces are all built on top of a trained model, each has different top layers and output types designed to accomodate their specific NLP task.
We’ll load XLNetForSequenceClassification. This is the normal XLNet model with an added single linear layer on top for classification that we will use as a sentence classifier. As we feed input data, the entire pre-trained XLNet model and the additional untrained classification layer is trained on our specific task.
The Fine-Tuning Process
Because the pre-trained model layers already encode a lot of information about the language, training the classifier is relatively inexpensive. Rather than training every layer in a large model from scratch, it’s as if we have already trained the bottom layers 95% of where they need to be, and only really need to train the top layer, with a bit of tweaking going on in the lower levels to accomodate our task.
Sometimes practicioners will opt to “freeze” certain layers when fine-tuning, or to apply different learning rates, apply diminishing learning rates, etc. all in an effort to preserve the good quality weights in the network and speed up training (often considerably). In fact, recent research on transfer learning models like BERT specifically has demonstrated that freezing the majority of the weights results in only minimal accuracy declines, but there are exceptions and broader rules of transfer learning that should also be considered. For example, if your task and fine-tuning dataset is very different from the dataset used to train the transfer learning model, freezing the weights may not be a good idea. We’ll cover the broader scope of transfer learning in NLP in a future post.
OK, let’s load XLNet! There are a few different pre-trained XLNet models available. “xlnet-base-cased” means the version that has both upper and lowercase letters (“cased”) and is the smaller version of the two (“base” vs “large”).
# Load XLNEtForSequenceClassification, the pretrained XLNet model with a single linear classification layer on top.
model = XLNetForSequenceClassification.from_pretrained("xlnet-base-cased", num_labels=2)
model.cuda()
Now that we have our model loaded we need to grab the training hyperparameters from within the stored model.
For the purposes of fine-tuning, the authors recommend the following hyperparameters in the following ranges (broken down by which NLP dataset they are applied to):

param_optimizer = list(model.named_parameters())
no_decay = ['bias', 'gamma', 'beta']
optimizer_grouped_parameters = [
{'params': [p for n, p in param_optimizer if not any(nd in n for nd in no_decay)],
'weight_decay_rate': 0.01},
{'params': [p for n, p in param_optimizer if any(nd in n for nd in no_decay)],
'weight_decay_rate': 0.0}
]
# This variable contains all of the hyperparemeter information our training loop needs
optimizer = AdamW(optimizer_grouped_parameters,
lr=2e-5)
Below is our training loop. There’s a lot going on, but fundamentally for each pass in our loop we have a training phase and a validation phase. At each pass we need to:
Training loop:
- Tell the model to compute gradients by setting the model in train mode
- Unpack our data inputs and labels
- Load data onto the GPU for acceleration
- Clear out the gradients calculated in the previous pass. In pytorch the gradients accumulate by default (useful for things like RNNs) unless you explicitly clear them out
- Forward pass (feed input data through the network)
- Backward pass (backpropagation)
- Tell the network to update parameters with optimizer.step()
- Track variables for monitoring progress
Evalution loop:
- Tell the model not to compute gradients by setting th emodel in evaluation mode
- Unpack our data inputs and labels
- Load data onto the GPU for acceleration
- Forward pass (feed input data through the network)
- Compute loss on our validation data and track variables for monitoring progress
So please read carefully through the comments to get an understanding of what’s happening. If you’re unfamiliar with pytorch a quick look at some of their beginner tutorials will help show you that training loops really involve only a few simple steps; the rest is usually just decoration and logging.
# Function to calculate the accuracy of our predictions vs labels
def flat_accuracy(preds, labels):
pred_flat = np.argmax(preds, axis=1).flatten()
labels_flat = labels.flatten()
return np.sum(pred_flat == labels_flat) / len(labels_flat)
# Store our loss and accuracy for plotting
train_loss_set = []
# Number of training epochs (authors recommend between 2 and 4)
epochs = 4
# trange is a tqdm wrapper around the normal python range
for _ in trange(epochs, desc="Epoch"):
# Training
# Set our model to training mode (as opposed to evaluation mode)
model.train()
# Tracking variables
tr_loss = 0
nb_tr_examples, nb_tr_steps = 0, 0
# Train the data for one epoch
for step, batch in enumerate(train_dataloader):
# Add batch to GPU
batch = tuple(t.to(device) for t in batch)
# Unpack the inputs from our dataloader
b_input_ids, b_input_mask, b_labels = batch
# Clear out the gradients (by default they accumulate)
optimizer.zero_grad()
# Forward pass
outputs = model(b_input_ids, token_type_ids=None, attention_mask=b_input_mask, labels=b_labels)
loss = outputs[0]
logits = outputs[1]
train_loss_set.append(loss.item())
# Backward pass
loss.backward()
# Update parameters and take a step using the computed gradient
optimizer.step()
# Update tracking variables
tr_loss += loss.item()
nb_tr_examples += b_input_ids.size(0)
nb_tr_steps += 1
print("Train loss: {}".format(tr_loss/nb_tr_steps))
# Validation
# Put model in evaluation mode to evaluate loss on the validation set
model.eval()
# Tracking variables
eval_loss, eval_accuracy = 0, 0
nb_eval_steps, nb_eval_examples = 0, 0
# Evaluate data for one epoch
for batch in validation_dataloader:
# Add batch to GPU
batch = tuple(t.to(device) for t in batch)
# Unpack the inputs from our dataloader
b_input_ids, b_input_mask, b_labels = batch
# Telling the model not to compute or store gradients, saving memory and speeding up validation
with torch.no_grad():
# Forward pass, calculate logit predictions
output = model(b_input_ids, token_type_ids=None, attention_mask=b_input_mask)
logits = output[0]
# Move logits and labels to CPU
logits = logits.detach().cpu().numpy()
label_ids = b_labels.to('cpu').numpy()
tmp_eval_accuracy = flat_accuracy(logits, label_ids)
eval_accuracy += tmp_eval_accuracy
nb_eval_steps += 1
print("Validation Accuracy: {}".format(eval_accuracy/nb_eval_steps))
Epoch: 0%| | 0/4 [00:00<?, ?it/s][A[A[A[A
Train loss: 0.41825219902260174
Epoch: 25%|██▌ | 1/4 [04:21<13:03, 261.11s/it][A[A[A[A
Validation Accuracy: 0.7901234567901234
Train loss: 0.3014157411653966
Epoch: 50%|█████ | 2/4 [08:41<08:41, 260.93s/it][A[A[A[A
Validation Accuracy: 0.7993827160493827
Train loss: 0.21351250676878755
Epoch: 75%|███████▌ | 3/4 [13:02<04:20, 260.77s/it][A[A[A[A
Validation Accuracy: 0.7866512345679012
Train loss: 0.15859863031423685
Epoch: 100%|██████████| 4/4 [17:22<00:00, 260.69s/it][A[A[A[A
[A[A[A[A
Validation Accuracy: 0.80054012345679
Training Evaluation
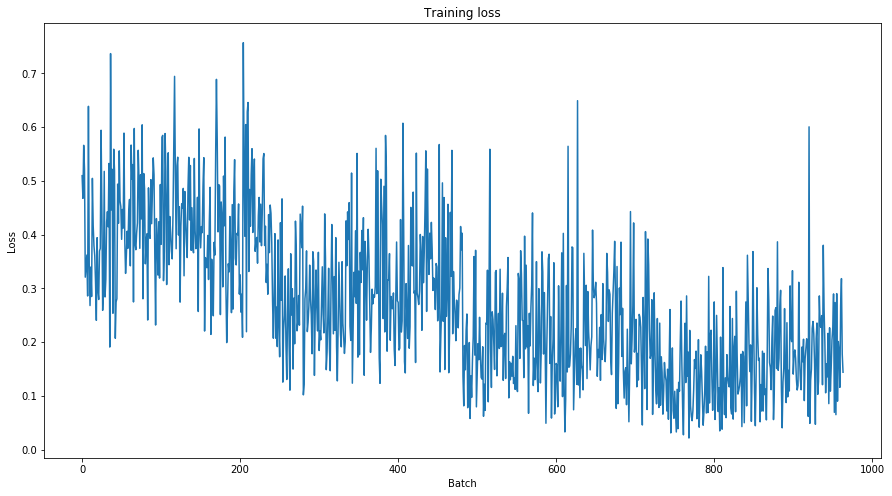
Let’s take a look at our training loss over all batches:
plt.figure(figsize=(15,8))
plt.title("Training loss")
plt.xlabel("Batch")
plt.ylabel("Loss")
plt.plot(train_loss_set)
plt.show()
Predict and Evaluate on Holdout Set
Now we’ll load the holdout dataset and prepare inputs just as we did with the training set. Then we’ll evaluate predictions using Matthew’s correlation coefficient because this is the metric used by the wider NLP community to evaluate performance on CoLA. With this metric, +1 is the best score, and -1 is the worst score. This way, we can see how well we perform against the state of the art models for this specific task.
# Upload the test file from your local drive
from google.colab import files
uploaded = files.upload()
<input type="file" id="files-4a18c006-c88f-4917-a4d0-d40b6290cce1" name="files[]" multiple disabled />
<output id="result-4a18c006-c88f-4917-a4d0-d40b6290cce1">
Upload widget is only available when the cell has been executed in the
current browser session. Please rerun this cell to enable.
</output>
<script src="/nbextensions/google.colab/files.js"></script>
Saving out_of_domain_dev.tsv to out_of_domain_dev.tsv
df = pd.read_csv("out_of_domain_dev.tsv", delimiter='\t', header=None, names=['sentence_source', 'label', 'label_notes', 'sentence'])
# Create sentence and label lists
sentences = df.sentence.values
# We need to add special tokens at the beginning and end of each sentence for XLNet to work properly
sentences = [sentence + " [SEP] [CLS]" for sentence in sentences]
labels = df.label.values
tokenized_texts = [tokenizer.tokenize(sent) for sent in sentences]
MAX_LEN = 128
# Use the XLNet tokenizer to convert the tokens to their index numbers in the XLNet vocabulary
input_ids = [tokenizer.convert_tokens_to_ids(x) for x in tokenized_texts]
# Pad our input tokens
input_ids = pad_sequences(input_ids, maxlen=MAX_LEN, dtype="long", truncating="post", padding="post")
# Create attention masks
attention_masks = []
# Create a mask of 1s for each token followed by 0s for padding
for seq in input_ids:
seq_mask = [float(i>0) for i in seq]
attention_masks.append(seq_mask)
prediction_inputs = torch.tensor(input_ids)
prediction_masks = torch.tensor(attention_masks)
prediction_labels = torch.tensor(labels)
batch_size = 32
prediction_data = TensorDataset(prediction_inputs, prediction_masks, prediction_labels)
prediction_sampler = SequentialSampler(prediction_data)
prediction_dataloader = DataLoader(prediction_data, sampler=prediction_sampler, batch_size=batch_size)
# Prediction on test set
# Put model in evaluation mode
model.eval()
# Tracking variables
predictions , true_labels = [], []
# Predict
for batch in prediction_dataloader:
# Add batch to GPU
batch = tuple(t.to(device) for t in batch)
# Unpack the inputs from our dataloader
b_input_ids, b_input_mask, b_labels = batch
# Telling the model not to compute or store gradients, saving memory and speeding up prediction
with torch.no_grad():
# Forward pass, calculate logit predictions
outputs = model(b_input_ids, token_type_ids=None, attention_mask=b_input_mask)
logits = outputs[0]
# Move logits and labels to CPU
logits = logits.detach().cpu().numpy()
label_ids = b_labels.to('cpu').numpy()
# Store predictions and true labels
predictions.append(logits)
true_labels.append(label_ids)
# Import and evaluate each test batch using Matthew's correlation coefficient
from sklearn.metrics import matthews_corrcoef
matthews_set = []
for i in range(len(true_labels)):
matthews = matthews_corrcoef(true_labels[i],
np.argmax(predictions[i], axis=1).flatten())
matthews_set.append(matthews)
/usr/local/lib/python3.6/dist-packages/sklearn/metrics/classification.py:872: RuntimeWarning: invalid value encountered in double_scalars
mcc = cov_ytyp / np.sqrt(cov_ytyt * cov_ypyp)
The final score will be based on the entire test set, but let’s take a look at the scores on the individual batches to get a sense of the variability in the metric between batches.
matthews_set
[0.049286405809014416,
0.014456362470655182,
0.5510387687779837,
0.2757127976394358,
-0.007053982594841415,
0.6397114734243627,
0.6831300510639732,
-0.06788442333021306,
0.5673665146135802,
0.4581228472908512,
0.39405520311955033,
0.6546536707079772,
0.6979824404521128,
0.5447047794019222,
0.5447047794019222,
0.41281272698065485,
0.0]
# Flatten the predictions and true values for aggregate Matthew's evaluation on the whole dataset
flat_predictions = [item for sublist in predictions for item in sublist]
flat_predictions = np.argmax(flat_predictions, axis=1).flatten()
flat_true_labels = [item for sublist in true_labels for item in sublist]
matthews_corrcoef(flat_true_labels, flat_predictions)
0.44330083840744616
Cool, we’ve fine-tuned XLNet!
Our initial score isn’t great, so it would be a good idea to try out some hyperparameter tuning (adjusting the learning rate, epochs, batch size, optimizer properties, etc.) in order to get a better score. I should also mention we didn’t train on the entire training dataset, but set aside a portion of it as our validation set for legibililty of code.
Conclusion
This post shows how to quickly and efficiently train an XLNet model with the huggingface pytorch interface.