BERT Research - Ep. 1 - Key Concepts & Sources
1. Introduction
In this “research notes” blog post, and the ones that follow it, I’ll be sharing what I am learning about BERT, as well as identifying the areas where I am perhaps confused or where I still need to learn more.
I think that the NLP community is currently missing an in-depth tutorial on the BERT model which does not require extensive background knowledge in LSTMs and Attention. More on this in the “Objectives” section.
My hope is that these research posts will:
- Help you begin to understand BERT sooner, before my final tutorial is written.
- Provide an opportunity for me to:
- Work out what I want to say, and how I ultimately want to organize the material.
- Get early feedback on my explanations before publishing.
You can read through this post, or just use it as a reference for the YouTube video:
Contents
By Chris McCormick
1.1. Objectives for the BERT Tutorial
My eventual goal for this tutorial is to explain “the inner workings“ of the BERT architecture.
I’ve found that a powerful approach to creating great tutorials is, while researching and learning about the topic, to pay very close attention to what terms and concepts feel alien or confusing to me.
Understanding what people are likely to feel confused by seems almost as valuable as understanding the topic itself!
Luckily, I felt profoundly ignorant as I first dove into BERT. I do have a wide range of knowledge in the field of Machine Learning (I have a strong understanding of neural networks,deep learning, and know a lot about word embeddings), but fairly little in RNNs and LSTMs, or in Attention and Transformers. I also hadn’t studied the topics of Neural Machine Translation (NMT) or Natural Language Inferencing (NLI) (a.k.a. “Textual Entailment”).
Because BERT is a departure from the LSTM-based approaches to NLP, I would like to create a tutorial which someone relatively new to NLP could read and understand in detail, without first learning about LSTMs (which seem to be very complicated in their own right!).
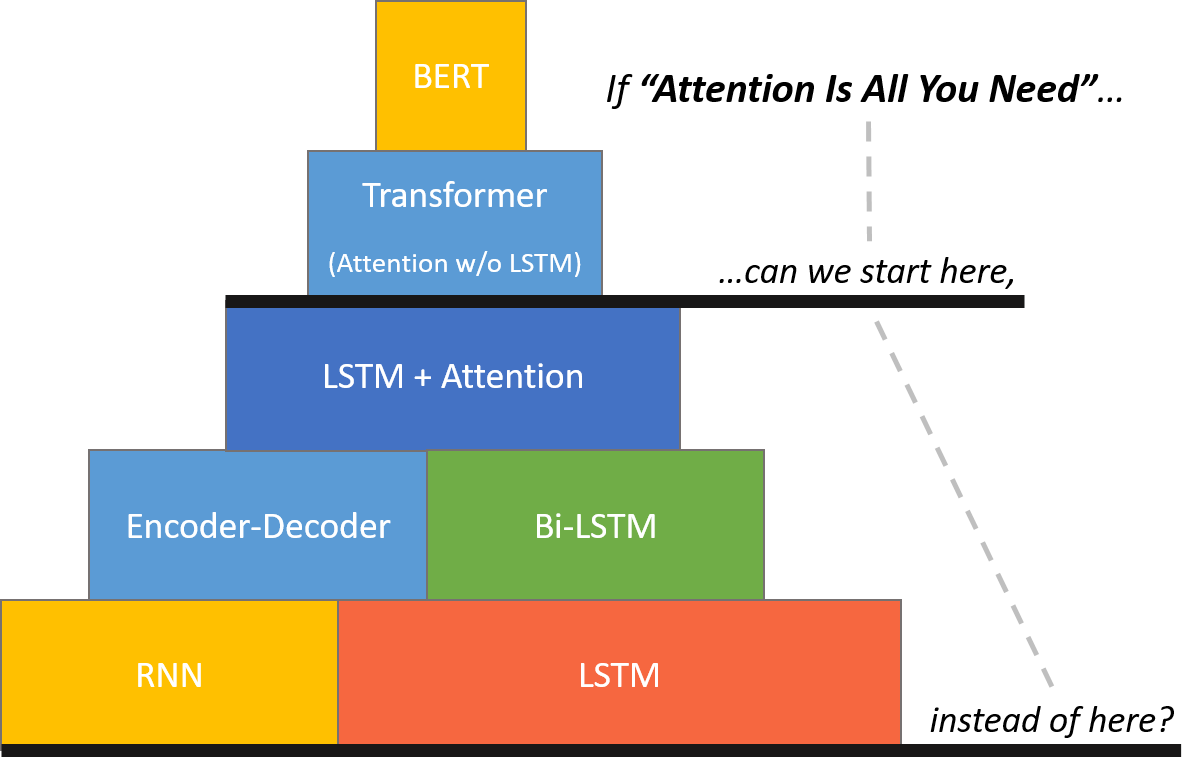
I affectionately call the above illustration “BERT Mountain” :).
1.2. Improvements on BERT
I am aware that the original BERT model has been outperformed on the GLUE benchmarks (RoBERTa, XLNet, …), and that new models are coming out every handful of months which manage to one-up the prior state of the art.
I am guessing, though, that BERT will stand as a landmark model, similar to how AlexNet did for the ImageNet challenge. I also expect that understanding BERT will be a good stepping stone for understanding other models and further advancements. Reading this short article has helped assure me that the new models aren’t major departures from BERT.
BERT also seems to be the strongest keyword–the most common entry point for people looking to understand these models.
Once I know more about BERT, and the differences between it and its successors, I will do my best to make the tutorial valuable to understanding the bigger concepts, and not just the details of one specific model (BERT).
2. Initial Sources
Here some of the primary sources of information about BERT–each of these is either highly authoratative (e.g., research papers) or which I understand to be highly regarded (popular blog posts).
Again, all of these require prior knowledge of LSTMs, the Encoder-Decoder approach, and Attention, so they haven’t worked for me as starting points! I expect them to be more valuable once I have learned some of the basics.
2.1. The BERT Paper & Resources
BERT Paper

- Paper: BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
- Submitted: Oct 11, 2018
- First Author: Jacob Devlin, Google AI Language
Can we start here?
I’ve heard that the BERT paper is well-written and not too difficult to follow. However, this excerpt from the paper makes it clear that we won’t get much from it without first understanding more about what a “Transformer” model is.
“BERT’s model architecture is a multi-layer bidirectional Transformer encoder based on the original implementation described in Vaswani et al. (2017) and released in the tensor2tensor library. Because the use of Transformers has become common and our implementation is almost identical to the original, we will omit an exhaustive background description of the model architecture and refer readers to Vaswani et al. (2017) as well as excellent guides such as “The Annotated Transformer”.”
This paragraph suggests that the “original transformer” was described in the paper “Attention is all you need” (cited as Vaswani et al. (2017)), and was also implemented in the tensor2tensor library released on tensorflow. It also references “The Annotated Transformer” blog post as a source for understanding Transformers. So I’ll add all of these to our list of primary sources.
BERT Repo
- GitHub Repo: github.com/google-research/bert
- Initial Commit: Oct 31, 2018
Not long after the paper was submitted, the authors published the implementation publicly on GitHub. You can see that this has become a very popular repository, with many stars, forks, and discussions happening in the “issues” section.
BERT Announcement Post

- Google Blog Post: Open Sourcing BERT: State-of-the-Art Pre-training for Natural Language Processing
- Published: Nov 2, 2018
- Authors: Jacob Devlin, Ming-Wei Chang
This short post might be worth reading as a high-level overview of the significance of BERT.
2.2. Attention is all you need (Paper)

- Paper: Attention is all you need
- Submitted: Jun 12, 2017
- First Author: Ashish Vaswani, Google Brain
This is the paper which introduced the Transformer architecture. BERT is just a big stack of Transformers. BERT came out about 16 months later.
The blog post in the next section contains the full text of this paper, so it probably makes more sense to read that post instead of the original paper?
2.3. The Annotated Transformer (Blog Post)
- Link: https://nlp.seas.harvard.edu/2018/04/03/attention.html
- Published: Apr 3, 2018
- Author: Alexander Rush, Harvard NLP
This blog post is a Python Notebook. It includes all of the original text of the article, and Rush has injected his own comments, as well as code for implementing the Transformer using PyTorch.
There is terminology here which comes from sequence models, and “Attention” is of course a key concept, so I don’t think this material is understandable without a strong background in Recurrence and Attention first.
2.4. Jay Alammar’s Posts
Jay’s blog posts are well written and very “readable”, largely due to his excellent illustrations.
If you already have a good background in LSTMs, then I suspect that going through these posts may be one of the easiest ways to make sense of BERT currently. I’ll have to come back and offer a more complete opinion on them once I’m further along in my understanding.
- BERT —— The Illustrated BERT, ELMo, and co. (How NLP Cracked Transfer Learning)
- Published: Dec 3, 2018
- Transformer —— The Illustrated Transformer
- Published: Jun 27, 2018
- Attention —— Visualizing A Neural Machine Translation Model (Mechanics of Seq2seq Models With Attention)
- Published: May 9, 2018
2.5. Sequence Models Course on Coursera
https://www.coursera.org/learn/nlp-sequence-models/home/
If you are missing the background in Recurrent Neural Networks and LSTMs, then I recommend Andrew Ng’s Sequence Models course on Coursera.
This course covers the following concepts, which I’ve seen come up in the material related to BERT:
- RNNs
- Encoder-Decoder
- LSTMs
- Bidirectional RNN
- Attention
I’m a big fan of Andrew’s, and his introductory Machine Learning course is my all-time favorite class that I’ve taken. A big part of what I enjoy is that he teaches (and expects you to learn) more of the technical details than other material out there. This makes the course difficult, but it is doable if you’re committed!
You can check it out for 7 days for free, and after that it’s $50 per month.
3. Next Up
The “holy grail” for me with this tutorial (i.e., my biggest goal) is to provide a clear, detailed, and well illustrated explanation of the Transformer architecture in BERT without expecting the reader to have a strong background in recurrence or LSTMs, or even Attention in the context of LSTMs.
It will take some time to get there, but in the mean time, there are a number of important concepts we can cover which are more easily accessible.
3.1. Input Representation & WordPiece Embeddings
I think a great place to start will be to look at the details and mechanics of how you feed text into a BERT model. Along with this, we can talk about the approach uses for creating embeddings for words with the “WordPiece” approach.
Both of these topics are covered in this post by Nick Ryan and myself, but I plan to create a dedicated post and video to expand on these insights.
3.2. BERT Applications
Once we’ve covered the input representation, we can then look at the output of the BERT model, and ways that we can apply BERT to different applications.
This post, for example, shows how to apply BERT to text classification.
3.3. BERT Training Tasks
BERT was trained on two “fake tasks”: “Masked Word Prediction” and “Next Sentence Prediction”.
By “fake task” I mean a task which:
- Isn’t actually that interesting or useful,
- May not even be possible to perform well,
- But for which we have vast amounts of training data–all we need is human-written text.
BERT is trained on these fake tasks because, as a byproduct of learning to do these tasks, it develops the ability to make sense of human language.
Once the training is finished, we strip off the final layer(s) of the model which were specific to the fake task, and then apply BERT to the tasks that we actually care about.
As I understand it, coming up with these two “fake tasks” is the real innovation of BERT–otherwise it’s just a large stack of Transformers, which had already been around.
Of course, another key contribution might be Google researchers having the text data, compute resources, and audacity to train such a huge model :).
3.4. BERT Transformer Architecture
I’m not sure yet how this part of the research will play out. Ideally I will gradually share insights about the Transformer architecture as I learn them, but we’ll just have to see how it goes!