How to Apply BERT to Arabic and Other Languages
Up to this point, our tutorials have focused almost exclusively on NLP applications using the English language. While the general algorithms and ideas extend to all languages, the huge number of resources that support English language NLP do not extend to all languages. For example, BERT and BERT-like models are an incredibly powerful tool, but model releases are almost always in English, perhaps followed by Chinese, Russian, or Western European language variants.
For this reason, we’re going to look at an interesting category of BERT-like models referred to as Multilingual Models, which help extend the power of large BERT-like models to languages beyond English.
by Chris McCormick and Nick Ryan
Contents
S1. Multilingual Models
1.1. Multilingual Model Approach
Multilingual models take a rather bizarre approach to addressing multiple languages…
Rather than treating each language independently, a multilingual model is pre-trained on text coming from a mix of languages!
In this post and the accompanying Notebooks, we’ll be playing with a specific multilingual model named XLM-R from Facebook (short for “Cross-Lingual Language Model - Roberta”).
While the original BERT was pre-trained on English Wikipedia and BooksCorpus (a collection of self-published books) XLM-R was pre-trained on Wikipedia and Common Crawl data from 100 different languages! Not 100 different models trained on 100 different languages, but a single BERT-type model that was pre-trained on all of this text together.
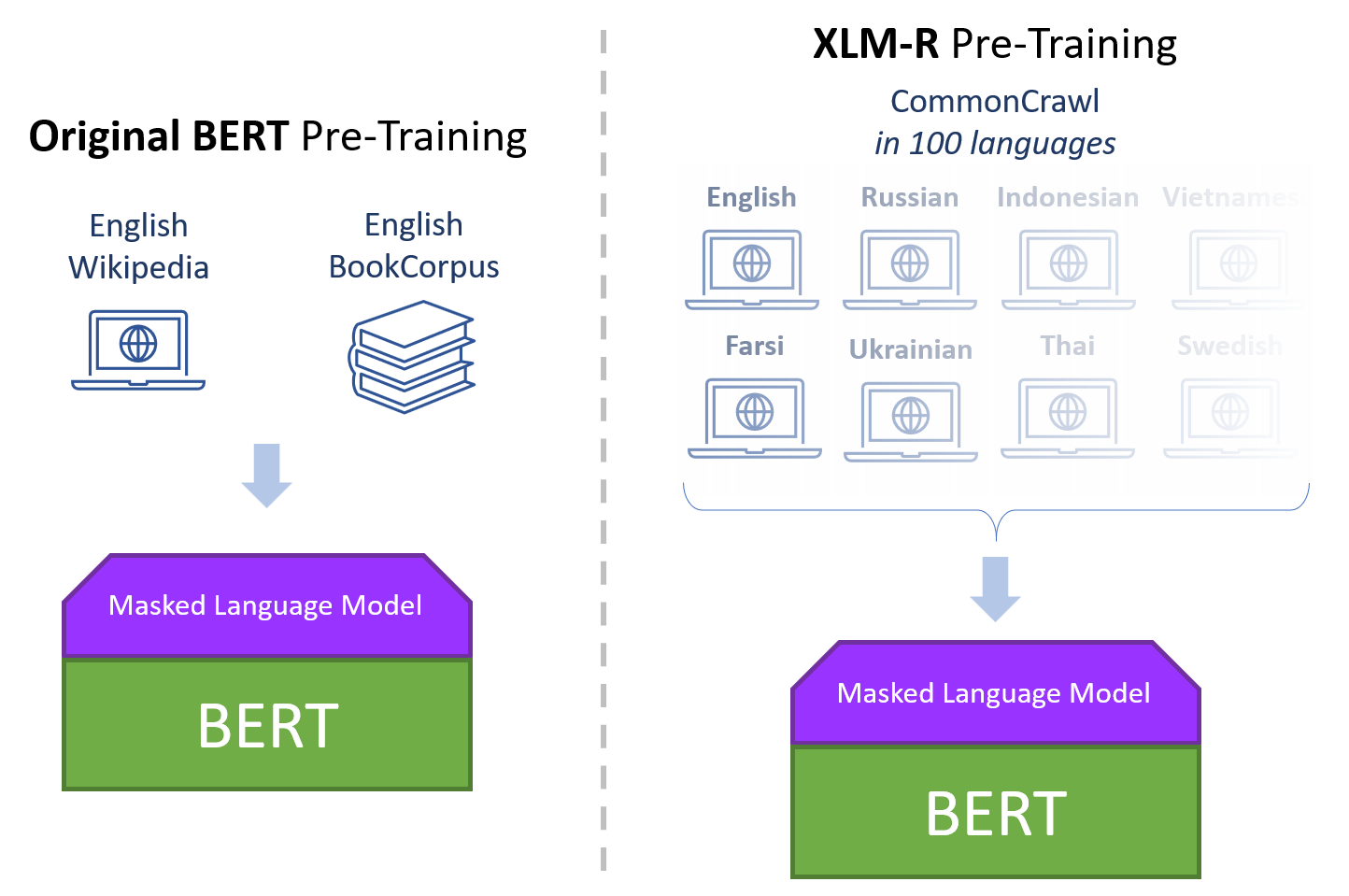
There really isn’t anything here that’s trying to deliberately differentiate between languages. For example, in XLM-R:
- There is a single, shared vocabulary (with 250k tokens) to cover all 100 languages.
- There is no special marker added to the input text to indicate what language it is.
- It wasn’t trained with “parallel data” (the same sentence in multiple languages).
- We haven’t modified the training objective to encourage it to learn how to translate.
And yet, instead of predicting nonsense or having only the barest understanding of any of its many input languages, XLM-R performs surprisingly well, even compared to models trained on a single language!
1.2. Cross-Lingual Transfer
If your application is in another language (we’ll use Arabic as the example from here on out), you can use XLM-R the same way you would regular BERT. You can fine-tune XLM-R on your Arabic training text, and then use it to make predictions in Arabic.
However, XLM-R allows you to leverage another technique that’s even more surprising…
Let’s say you are trying to build a model to automatically identify nasty (or “toxic”) user comments in Arabic. There’s already a great dataset out there for this called “Wikipedia Toxic Comments” with roughly 225k labeled comments–except that it’s all in English!
What are your options? Gathering a similar-sized dataset in Arabic would have to be costly. Applying Machine Translation in some way could be interesting, but has its limitations (I’ll discuss translation more in a later seciton).
XLM-R provides another avenue called “Cross-Lingual Transfer”. You can fine-tune XLM-R on the Wikipedia Toxic Comments dataset in English, and then apply it to Arabic comments!

XLM-R is able to take it’s task-specific knowledge that it learned in English and apply it to Arabic, even though we never showed it any Arabic examples! It’s the concept of transfer learning applied from one language to another–thus, “Cross-Lingual Transfer”.
In the Notebooks accompanying this post, we’ll see that training XLM-R purely on ~400k English samples actually yields better results than fine-tuning a “monolingual” Arabic model on (a much smaller) Arabic dataset.
This impressive feat is referred to as Zero-Shot Learning or Cross-Lingual Transfer.
1.3. Why Multilingual?
Multilingual models and cross-lingual transfer are cool tricks, but wouldn’t it be better if Facebook just trained and published a separate model for each of these different languages?
That would probably produce the most accurate models, yes–if only there was as much text available online in every language as there is English!
A model pre-trained on text from only a single language is called monolingual, while those trained on text from multiple languages are called multilingual.
The following bar plot shows, for a small selection of languages, how much text data the authors of XLM-R were able to gather for pre-training.
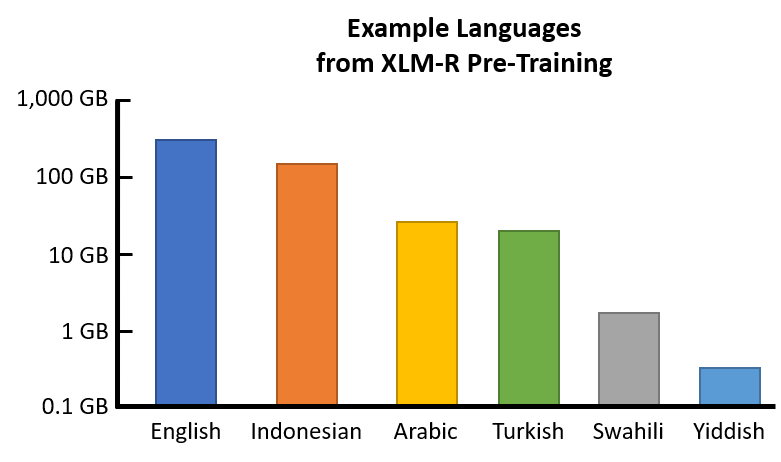
Note that the scale is logarithmic, so there is roughly 10x more English data than Arabic or Turkish, and 1,000x more English than Yiddish.
1.4. Languages by Resource
Different languages have different amounts of training data available to create large, BERT-like models. These are referred to as high, medium, and low-resource languages. High-resource languages like English, Chinese, and Russian have lots of freely available text online that can be used as training data. As a result, NLP researchers have largely focused on developing large language models and benchmarks in these languages.
I adapted the above bar plot from Figure 1 of the XLM-R paper. Here is their full bar plot, which shows the amount of data they gathered for 88 of the 100 languages.
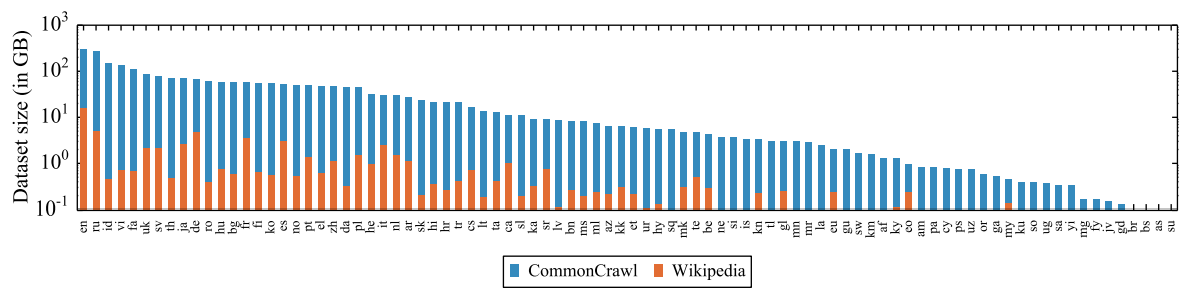
The languages are labeled using two-letter ISO codes–you can look them up in the table here.
Here are the first ten codes in the bar plot (note that there are another ~10 languages after German with a similar amount of data).
| Code | Language |
|---|---|
| en | English |
| ru | Russian |
| id | Indonesian |
| vi | Vietnamese |
| fa | Persian / Farsi |
| uk | Ukranian |
| sv | Swedish |
| th | Thai |
| ja | Japanese |
| de | German |
Note that this ranking of “quantity of data” does not match the rankings of how many users there are on the internet in each language. Check out this table on Wikipedia. Chinese (code zh) is number 21 in the bar plot, but by far has the most users (after English).
Similarly, the amount of effort and attention given to different languages by NLP researchers does not follow the ranking in the bar plot–otherwise Chinese and French would be in the top 5.
There is a recent project called OSCAR which provides large amounts of text for pre-training BERT-like models in different languages–definitely worth checking out if you’re looking for unlabeled text to use for pre-training in your language!
1.5. Leveraging Machine Translation
It’s also possible to involve “Machine Translation” (machine learning models that automatically translate text) to try and help with this problem of limited language resources. Here are two common approaches.
Approach #1 - Translate Everything
You could rely entirely on English models, and translate any and all Arabic text in your application to English.

This approach has the same problems as the monolingual model approach. The best translation tools use machine learning, and have the same limitation around available training data. In other words, the translation tools for medium and low resource languages aren’t good enough to be an easy solution to our problem–currently, a multilingual BERT model like XLM-R is probably the better way to go.
Approach #2 - Augment Training Data
If there already exists a large amount of labeled English text for your task, then you could translate this labeled text into Arabic and use it to augment your available Arabic training data.

If there is a decent monolingual model available in your language, and there is a large English dataset available for your task, then this is a great technique. We applied this technique to Arabic in one of our accompanying Notebooks and it outperformed XLM-R (at least in our initial results–we didn’t perform a rigorous benchmark).
1.6. XLM-R Vocabulary
As you might imagine, XLM-R has a very different vocabulary than the original BERT, in order to accomodate 100 different languages.
XLM-R has a vocabulary of 250,000 tokens, vs. BERT’s 30,000 tokens.
I’ve published a Notebook here where I’ve poked around XLM-R’s vocabulary to get a sense for what it contains and to gather various statistics.
Here are some highlights:
- It contains an “alphabet” of 13,828 characters.
- It is 62% whole-words and 38% sub-words.
- To count English words, I tried looking up all whole-words in WordNet (a kind of comprehensive English dictionary), and found ~11,400 English words, which is only 5% of XLM-R’s vocabulary.
S2. Comparing Approaches
2.1. Natural Language Inferencing
The most commonly used task for evaluating multilingual models is called Natural Language Inferencing (NLI). The reason for this is that there is an excellent multilingual benchmark dataset available called XNLI.
We’ll look at XNLI in the next section, but here’s an explanation of the basic NLI task, in case you aren’t familiar.
In NLI, we are given two sentences: (1) a “premise” and (2) a “hypothesis” and asked to determine whether:
- 2 follows logically from 1 (This is called “entailment”)
- 2 contradicts 1 (“contradiction”)
- 2 has no effect on 1 (“neutral”)
Here are some examples:
| Premise | Label | Hypothesis |
|---|---|---|
| The man inspects his uniform. | Contradiction | The man is sleeping. |
| An older and younger man smiling. | Neutral | Two men are smiling and laughing at the cats. |
| A soccer game with multiple males playing. | Entailment | Some men are playing a sport. |
As I understand it, NLI is primarily a benchmarking task rather than a practical application–it requires the model to develop some sophisticated skills, so we use it to evaluate and benchmark models like BERT.
2.2. Overview of MNLI and XNLI
Benchmarking multilingual models on NLI is done with a combination of two datasets named “MNLI” and “XNLI”.
MNLI will provide us with a large number of English training examples to fine-tune XLM-Roberta on the general task of NLI.
XNLI will provide us with a small number of NLI test examples in different languages. We’re going to take our XLM-Roberta model (which we’ll fine-tune only on the English MNLI examples) and apply it to the Arabic test cases from XNLI.
About MNLI
The Multi-Genre Natural Language Inference (MultiNLI or MNLI) corpus was published in 2018, and is a collection of more than 400,000 English sentence pairs annotated with textual entailment information.
In MNLI, ‘Multi’ refers to Multi-Genre, not Multilingual. Confusing, I know! It’s called “Multi-Genre” because it is intended as a successor to the Stanford NLI corpus (SNLI), which is composed entirely of somewhat simple sentences drawn from image captions. MNLI increases the difficulty of the task by adding multiple and more difficult “genres” of text like transcribed conversations, government documents, travel guides, etc.
This corpus contains 392,000 training examples, 20,000 “development examples” (test samples to use while developing your model), and 20,000 “test examples” (the final test set on which benchmark scores are reported).
Here are a few randomly-selected training examples
Premise:
If I had told you my ideas, the very first time you saw Mr. Alfred
Inglethorp that astute gentleman would have ”in your so expressive idiom
”'smelt a rat'!
Hypothesis:
In the event that I had revealed my ideas to you, Mr. Alfred would have been
absolutely oblivious to your knowledge of my ideas.
Label:
2 (contradiction)
----------------
Premise:
Like federal agencies, the organizations we studied must protect the
integrity, confidentiality, and availability of the information resources
they rely on.
Hypothesis:
Some organizations must protect the confidentiality of information they rely
on.
Label:
0 (entailment)
----------------
Premise:
Well? There was no change of expression in the dark melancholic face.
Hypothesis:
He just looked at me and said, Well, what is it?
Label:
0 (entailment)
----------------
About XNLI
“XNLI” stands for Cross-lingual Natural Language Inference corpus. The paper (here) was first submitted to arXiv in September, 2018.
This dataset consists of a smaller subset of examples from the MLNI dataset which have been human-translated to 14 different languages (for a total of 15 languages, if you include English):
| Index | Code | Language |
|---|---|---|
| 0 | ar | Arabic |
| 1 | bg | Bulgarian |
| 2 | de | German |
| 3 | el | Greek |
| 4 | en | English |
| 5 | es | Spanish |
| 6 | fr | French |
| 7 | hi | Hindi |
| 8 | ru | Russian |
| 9 | sw | Swahili |
| 10 | th | Thai |
| 11 | tr | Turkish |
| 12 | ur | Urdu |
| 13 | vi | Vietnamese |
| 14 | zh | Chinese |
XNLI does not provide training data for these different languages, so it’s intended as a benchmark for the crosslingual approach that we will be taking here.
For each language there are 5,000 test set sentence pairs and 2,500 development set sentence pairs.
Sam Bowman at NYU was behind both the MNLI and XNLI datasets. XNLI was done as a collaboration with Facebook.
Here are a few random examples from the test set for Arabic.
Premise:
في المسرحية الاجتماعي كذلك، فإن فرص العمل والتنسيق بين الأدوار المختلفة ربما
تساعد الأطفال على فهم أوجه التشابه والاختلاف بين الناس في الرغبات والمعتقدات
والمشاعر.
Hypothesis:
لا يستطيع الأطفال تعلم اى شئ .
Label:
2 (contradiction)
----------------
Premise:
لماذا ، كما كنت أخبر سيادته هنا ، من فكر مثلك أن وجود الأنسة بيشوب على متن
السفينة سيجعلنا أمنين ، ليس من أجل أمه ،ذاك النخاس القذر سكت عن ما هو مستحق
له .
Hypothesis:
لم أتحدّث إلى سيادته منذ زمن طويل.
Label:
2 (contradiction)
----------------
Premise:
لقد قذفت إعلان عن كوكاكولا هناك
Hypothesis:
ضع إعلان مشروب غازي.
Label:
1 (neutral)
----------------
2.3. Monolingual Approach
We created two Notebooks for this post–one for applying a monolingual model, and another for applying a multilingual model (XLM-R).
For the monolingual approach, I used a community-submitted model, asafaya/bert-base-arabic, from here. The documentation for this model shows that it was pre-trained on a large amount of Arabic text, and that it has a high number of downloads in the past 30 days (meaning it’s a popular choice).
I fine-tuned this model with two different approaches.
Approach #1 - Using a Small, Labeled Dataset
We can use the small validation set (2,500 human-translated Arabic examples) from XNLI as our training set. That’s a pretty small training set, especially compared to the ~400k examples in English MNLI! I imagine this approach is the most similar to what you could expect from trying to gather a labeled dataset yourself.
This approach yielded an accuracy of 61.0% on the Arabic XNLI test set. This is the lowest score of the various approaches we tried (there is a results table in a later section).
Approach #2 - Using Machine-Translated Examples
The authors of XNLI also provided Machine-Translated copies of the large English MNLI dataset for each of the 14 non-English languages.
This will provide us with ample training data, but presumably the quality of the data will be lower because the samples were translated by an imperfect machine learning model rather than a human.
This approach gave us an accuracy of 73.3% on the Arabic XNLI test set.
2.4. Multilingual Approach
For the Multilingual approach, I fine-tuned XLM-R against the full English MNLI training set.
Using the huggingface/transformers library, applying XLM-R is nearly identical to applying BERT, you just use different class names.
To use the monolingual approach, you can load the model and tokenizer with the following:
from transformers import BertTokenizer
from transformers import BertForSequenceClassification
# Load the tokenizer.
tokenizer = BertTokenizer.from_pretrained("asafaya/bert-base-arabic")
# Load the model.
model = BertForSequenceClassification.from_pretrained("asafaya/bert-base-arabic", num_labels = 3)
For XLM-R, this becomes:
from transformers import XLMRobertaTokenizer
from transformers import XLMRobertaForSequenceClassification
# Load the tokenizer.
xlmr_tokenizer = XLMRobertaTokenizer.from_pretrained("xlm-roberta-base" )
# Load the model.
xlmr_model = XLMRobertaForSequenceClassification.from_pretrained("xlm-roberta-base", num_labels=3)
Learning Rate
The rest of the code is identical. However, we did encounter a critical difference around parameter choices… We found that XLM-R required a smaller learning rate than BERT–we used 5e-6. When we tried 2e-5 (the smallest of the recommended learning rates for BERT), XLM-R training completely failed (the model’s performance never improved over random guessing). Note that 5e-6 is one-fourth of 2e-5.
Cross-Lingual Results
With this cross-lingual transfer approach, we got an accuracy of 71.6% on the Arabic XNLI test set. Compare that to the monolingual model fine-tuned on Arabic examples, which only scored 61.0%!
The authors of XML-RoBERTa reported a score of 73.8% on Arabic in their paper in Table 1:

The model in the bottom row of the table is larger–it matches the scale of BERT-large. We used the smaller ‘base’ size in our example.
Our lower accuracy may have to do with parameter choices like batch size, learning rate, and overfitting.
2.5. Results Summary
Again, my intent with these Notebooks was to provide working example code; not to perform rigorous benchmarks. To really compare approaches, more hyperparameter tuning should be done, and results should be averaged over multiple runs.
But here are the results we got with minimal tuning!
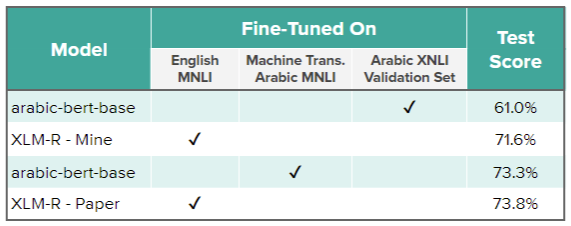
For rows 2-4 of the table, you can further improve these results by fine-tuning on the Arabic XNLI validation examples. (I tried this quickly with XLM-R and confirmed the score went up to 74.2%!)
2.6. Which Approach to Use?
Given that I was more easily able to achieve good results with arabic-bert-base, and knowing that it requires less memory (due to a smaller vocabulary), I think I would go with the monolingual model in this case.
However, this is only possible because a team pre-trained and released a good monolingual model for Arabic!
I was originally thinking to use Indonesian as my example language for this project, but
- Indonesian is not among the 15 XNLI languages.
- The best Indonesian model I found, cahya/bert-base-indonesian-522M, was pre-trained on a relatively modest amount of text (~0.5GB), and so I’m more skeptical of its performance.
For Indonesian, I would still want to try both approaches, but I suspect that XLM-R would come out ahead.
Example Notebooks
The two Notebooks referenced in this post (one implements the Multilingual experiments and the other implements the Monolingual experiments) are available to purchase from my site here. I also provide a walkthrough of these Notebooks on YouTube here.