How To Build Your Own Question Answering System
In this post, we’ll create a very simple question answering system that, given a natural language question, returns the most likely answers from a corpus of documents.
This represents an easy to follow and low-effort example of a question answering system that can still be of practical use for you own application if you choose to swap in your own dataset or build something more elaborate on top of this. Additionally, the concepts covered here will be useful in later posts when we look at variations of more complex questions answering systems.
This tutorial is also available as a Colab Notebook here.
by Nick Ryan
Contents
- Contents
- S1. Question Answering System Architecture
- S2. Setup
- S3. Import Dataset
- S4. TF-IDF Retriever
- S5. BERT-SQUAD Retriever
- S6. Putting It All Together
- S7. Conclusion
S1. Question Answering System Architecture
Our question answering system will take in a natural language question as input and will output natural language as an answer. The system consists of three primary components:
- An external knowledge source to query against
- In general, the knowledge source can be a collection of documents, tables, knowledge graphs, etc. that we are interested in searching through for answers. In our system, any collection of documents will work. For our example we will use the WikiBio dataset containing the first paragraph of thousands of English wikipedia biographies.
- A retriever to pull out relevant data from the knowledge source
- The retriever component searches through the dataset in order to find the most relevant data for the next stage of the model. This component can use any classic information retrieval technique like TF-IDF or, neural vectors, or models dedicated entirely to retrieval. The goal is simply to retrieve the data most relevant to answering the question.
- A reader / generator component to find the best answer
- This component is responsible for generating our answer. It can either retrieve exact spans of text from the dataset or can generate novel text using the question and data from the dataset. The goal is to use the question text and the retrieved data to generate the best answer. In our example, we will use BERT fine-tuned on the SQUAD dataset, which asks the model to extract a short answer from a reference text given some question. You can read all about BERT fine-tuned on SQUAD here!
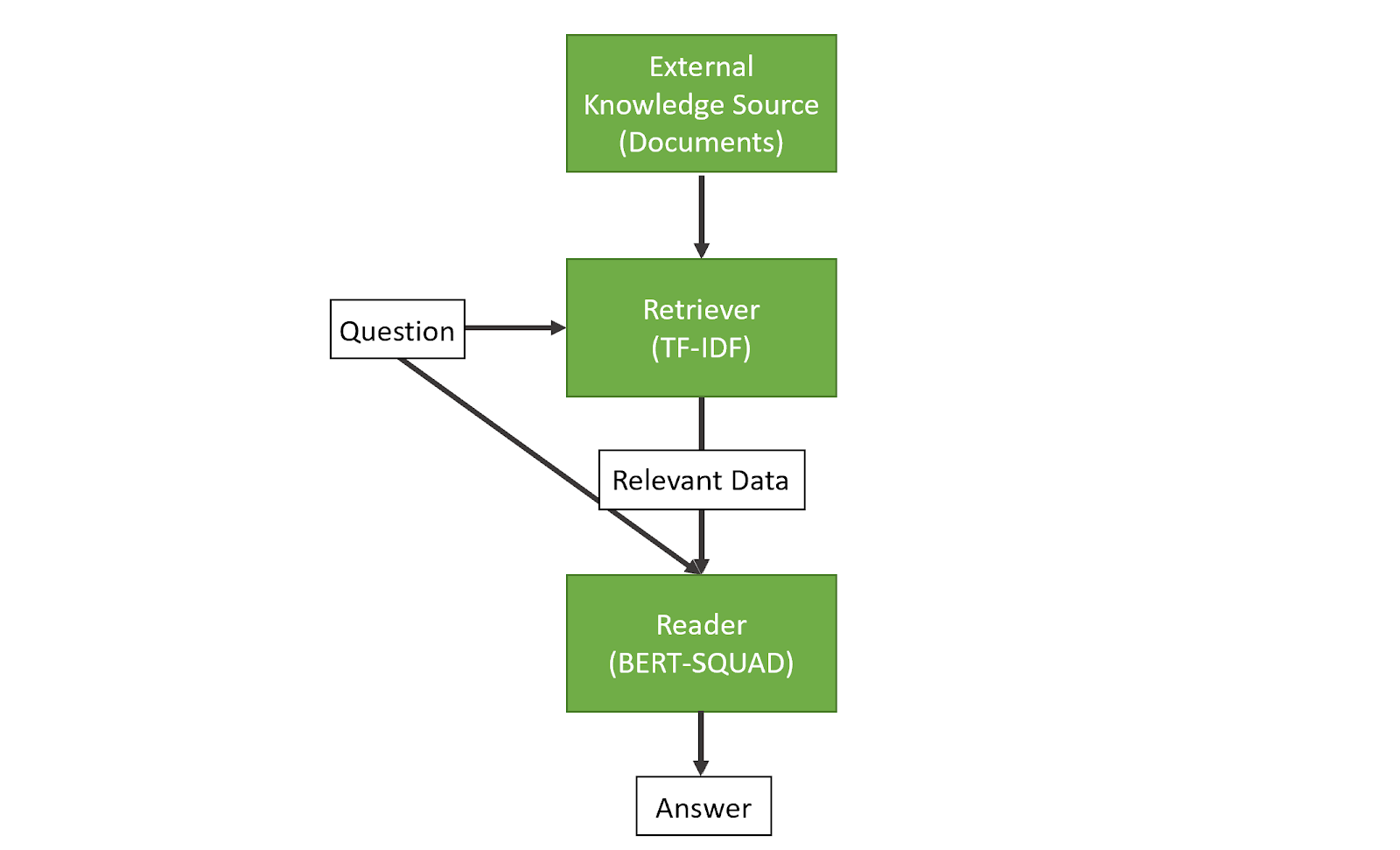
In this tutorial, we’ll combine a very simple and easy to understand retriever (TF-IDF) with a reader (BERT-SQUAD) to create our first question answering system.
S2. Setup
Let’s install some requirements for creating our question answering system
!pip install transformers
!pip install datasets
import torch
(Output removed from blog post)
S3. Import Dataset
Here we import a dataset that we’ll ask questions against. We’ll use a small selection from the WikiBio dataset and use the first paragraphs of Wikipedia biographies as our documents.
For our example we will use the WikiBio dataset containing the first paragraph of thousands of English wikipedia biographies. This will take a little while to download, so grab a cup of coffee or import your own dataset instead.
If you’re interested in applying this to your own application, all you have to do is insert your own dataset into the variable “docs” and everything else should be taken care of for you!
# Import the huggingface datasets library
from datasets import load_dataset
# Pull the first 100 biographies from the dataset
wiki_bio_dataset = load_dataset('wiki_bio', split='test[0:100]')
(Output removed from blog post)
# This is the plain text of the biographies
docs = wiki_bio_dataset['target_text']
Let’s take a quick look at a sample of the biographies:
for doc in docs[:3]:
print (doc)
leonard shenoff randle -lrb- born february 12 , 1949 -rrb- is a former major league baseball player .
he was the first-round pick of the washington senators in the secondary phase of the june 1970 major league baseball draft , tenth overall .
philippe adnot -lrb- born 25 august 1945 in rhèges -rrb- is a member of the senate of france .
he was first elected in 1989 , and represents the aube department .
a farmer by profession , he serves as an independent , and also serves as the head of the general council of aube , to which he was elected to represent the canton of méry-sur-seine in 1980 .
in 1998 and 2008 , he was re-elected to the senate in the first round , avoiding the need for a run-off vote .
having contributed to the creation of the university of technology of troyes , in 1998 he was made the first vice president of the university board , of which he is currently the president .
he is a member of the senate 's committee on the laws relating to the freedoms and responsibilities of universities .
as of 2009 , he serves as the delegate from the administrative meeting for senators not on the list of another group he is decorated as a chevalier of the ordre national de mérite agricole .
miroslav popov -lrb- born 14 june 1995 in dvůr králové nad labem -rrb- is a czech grand prix motorcycle racer .
he currently races in the fim cev moto2 championship for montaze broz racing team aboard a suter .
S4. TF-IDF Retriever
4.1 Document Segmenting
Now that we have our document corpus, we need to make sure that each document is short enough to fit into the 512 token limit of BERT. If a document is longer than 512 tokens, we’ll simply segment it into multiple smaller chunks and add them to the final corpus.
def segment_documents(docs, max_doc_length=450):
# List containing full and segmented docs
segmented_docs = []
for doc in docs:
# Split document by spaces to obtain a word count that roughly approximates the token count
split_to_words = doc.split(" ")
# If the document is longer than our maximum length, split it up into smaller segments and add them to the list
if len(split_to_words) > max_doc_length:
for doc_segment in range(0, len(split_to_words), max_doc_length):
segmented_docs.append( " ".join(split_to_words[doc_segment:doc_segment + max_doc_length]))
# If the document is shorter than our maximum length, add it to the list
else:
segmented_docs.append(doc)
return segmented_docs
4.2 Finding Relevant Documents
Next, our goal is to find within this corpus the subset of documents that are most likely to contain our answer, because running every single document through our BERT model is expensive and doesn’t help us narrow down a good answer. For this example, we’ll simply use the scikit-learn TF-IDF vectorizer to convert our documents and our query into vectors.
The document vectors with the highest cosine similarity to our query vector will be the best candidates to search for our answer, and we will feed these top candidate documents into the SQUAD model to get our predicted answers.
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.metrics.pairwise import cosine_similarity
def get_top_k_articles(query, docs, k=2):
# Initialize a vectorizer that removes English stop words
vectorizer = TfidfVectorizer(analyzer="word", stop_words='english')
# Create a corpus of query and documents and convert to TFIDF vectors
query_and_docs = [query] + docs
matrix = vectorizer.fit_transform(query_and_docs)
# Holds our cosine similarity scores
scores = []
# The first vector is our query text, so compute the similarity of our query against all document vectors
for i in range(1, len(query_and_docs)):
scores.append(cosine_similarity(matrix[0], matrix[i])[0][0])
# Sort list of scores and return the top k highest scoring documents
sorted_list = sorted(enumerate(scores), key=lambda x: x[1], reverse=True)
top_doc_indices = [x[0] for x in sorted_list[:k]]
top_docs = [docs[x] for x in top_doc_indices]
return top_docs
S5. BERT-SQUAD Retriever
5.1 Import Model
We’ll import a BERT model that has been fine-tuned on SQUAD, a task that asks the model to return the span of words most likely to contain the answer to a given question. This will serve as the reader component of our question answering system.
from transformers import BertTokenizer, BertForQuestionAnswering
model = BertForQuestionAnswering.from_pretrained('bert-large-uncased-whole-word-masking-finetuned-squad')
tokenizer = BertTokenizer.from_pretrained('bert-large-uncased-whole-word-masking-finetuned-squad')
(Output removed from blog post)
5.2 Calling the Model
Now, we create a function that takes as input a question and a reference text and returns the single span of words in the reference text that is most likely to be an answer to the input question. Again, you can visit our previous post here for a detailed explanation of the model.
def answer_question(question, answer_text):
input_ids = tokenizer.encode(question, answer_text, max_length=512)
# ======== Set Segment IDs ========
# Search the input_ids for the first instance of the `[SEP]` token.
sep_index = input_ids.index(tokenizer.sep_token_id)
# The number of segment A tokens includes the [SEP] token istelf.
num_seg_a = sep_index + 1
# The remainder are segment B.
num_seg_b = len(input_ids) - num_seg_a
# Construct the list of 0s and 1s.
segment_ids = [0]*num_seg_a + [1]*num_seg_b
# There should be a segment_id for every input token.
assert len(segment_ids) == len(input_ids)
outputs = model(torch.tensor([input_ids]), # The tokens representing our input text.
token_type_ids=torch.tensor([segment_ids]), # The segment IDs to differentiate question from answer_text
return_dict=True)
start_scores = outputs.start_logits
end_scores = outputs.end_logits
# ======== Reconstruct Answer ========
# Find the tokens with the highest `start` and `end` scores.
answer_start = torch.argmax(start_scores)
answer_end = torch.argmax(end_scores)
# Get the string versions of the input tokens.
tokens = tokenizer.convert_ids_to_tokens(input_ids)
# Start with the first token.
answer = tokens[answer_start]
# Select the remaining answer tokens and join them with whitespace.
for i in range(answer_start + 1, answer_end + 1):
# If it's a subword token, then recombine it with the previous token.
if tokens[i][0:2] == '##':
answer += tokens[i][2:]
# Otherwise, add a space then the token.
else:
answer += ' ' + tokens[i]
print('Answer: "' + answer + '"')
S6. Putting It All Together
Great, now everything is in place! Let’s ask our question answering system a question about something in our documents. I’ve already looked through the subset of WikiBio data and decided to ask some questions about one of the biographies.
# Enter our query here
query = "Who plays bass for Death From Above?"
#query = "What else does the bassist for Death From Above play?"
#query = "What projects is Jesse Keeler involved in?"
# Segment our documents
segmented_docs = segment_documents(docs, 450)
# Retrieve the top k most relevant documents to the query
candidate_docs = get_top_k_articles(query, segmented_docs, 3)
# Return the likeliest answers from each of our top k most relevant documents in descending order
for i in candidate_docs:
answer_question(query, i)
print ("Reference Document: ", i)
Answer: "jesse frederick keeler"
Reference Document: jesse frederick keeler -lrb- born november 11 , 1976 -rrb- is a canadian musician .
he is known as the bassist of canadian dance-punk duo death from above 1979 and one half of the electronic music duo mstrkrft .
in addition to singing , keeler plays drums , guitar , bass , keyboards , and saxophone , as well as work as a producer , lending to music of a variety of styles over the course of his career , including punk , hardcore , rock , house , and electro .
Answer: "jakob kreuzer"
Reference Document: jakob kreuzer -lrb- born 15 january 1995 -rrb- is an austrian footballer who plays for sv ried .
Answer: "andre fernando cabrita salvador"
Reference Document: andré fernando cabrita salvador -lrb- born 4 november 1993 in portimão -rrb- is a portuguese footballer who plays for portimonense s.c. as a midfielder .
S7. Conclusion
Cool! We have a system that can fairly quickly find the most relevant documents from our dataset and can then pull out the span of text most likely to answer our question. I’ve added a few more queries about this same person and our question answering system was able to answer them all correctly.
This question answering system is by no means perfect, and I encourage you to try out different questions or reference texts in order to break it. (You might try exploiting a weakness in the retriever by hiding the answer in a document that will likely get low TF-IDF scores, or you might try asking a question that requires the reader to incorporate or combine multiple pieces of knowledge that are not contained explicilty in the text.)
Imperfect as our system is, it represents a first step towards building a more advanced and robust question answering system. Along the way we have learned about a few of the basic components that will make understanding more complex models easier. Stay tuned for subsequent tutorials and content on question answering, chatbots, and conversational AI!