How Stable Diffusion Works
The ability for a computer to generate art from nothing but a written description is fascinating! I know that I, for one, would be desperately curious to see what’s actually going on “under the hood” that would make this possible, so I wanted to do what I can here to provide a less superficial explanation of what’s going on even for those who aren’t familiar with the concepts in artificial intelligence.
Overview
In the first section, I’ll give you the high-level explanation (that you may already be familiar with). It’s a good start, but I know that it wouldn’t satisfy my curiosity. 😉 I’d be asking, “Ok, great, but how does it do that?”
To address this, I’ll show you some of Stable Diffusion’s inner workings. The insides are more complex than you might be hoping, but I at least wanted to show you more concretely what’s going on, so that it’s not a complete mystery anymore.
More specifically:
- Stable Diffusion is a huge neural network.
- Neural networks are pure math.
- The truth is, we don’t fully know what it’s doing!
- Ultimately, Stable Diffusion works because we trained it.
But let’s start with the bigger picture!
Stable Diffusion Removes Noise from Images
If you’ve ever tried to take a picture when it’s too dark, and the picture came out all grainy, that graininess is an example of “noise” in an image.
We use Stable Diffusion to generate art, but what it actually does behind the scenes is “clean up” images!
It’s much more sophisticated than the noise removal slider in your phone’s image editor, though. It actually has an understanding of what the world looks like, and an understanding of written language, and it leverages these to guide the process.
For example, imagine if I gave the below image on the left to a skilled graphic artist and told them that it’s a painting of an alien playing a guitar in the style of H.R. Giger. I bet they could go in and painstakingly clean it up to create something like the image on the right.

(These are actual images from Stable Diffusion!)
The artist would do it using their knowledge of Giger’s artwork as well as knowledge of the world (such as what guitars are supposed to look like and how you play one). Stable Diffusion is essentially doing the same thing!
“Inference Steps”
Are you familiar with the “Inference Steps” slider in most art generation tools? Stable Diffusion removes noise incrementally.
Here’s an example of running it for 25 steps:

The alien guitarist example makes more sense, because you can make out what it’s supposed to be much more clearly… but in the image above, the starting image looks completely unrecognizable!
In fact, that noisy alien example was actually taken from about halfway through the process–it actually started out as complete noise as well!

How Does It Even Start?
To generate art, we give Stable Diffusion a starting image that’s actually nothing but pure noise. But, rather cruelly 😏, we lie and say “This is a super-noisy painting of an alien playing a guitar in the style of H.R. Giger–can you clean it up for me?”
If you gave that task to a graphic artist, they’d throw up their hands–“I can’t help you, the image is completely unrecognizable!”
So how does Stable Diffusion do it?
At the simplest level, the answer is that it’s a computer program and it has no choice but to do its thing and produce something for us.
A deeper answer has to do with the fact that AI models (more technically, “Machine Learning” models) like Stable Diffusion are heavily based on statistics. They estimate probabilities for all of their options, and even if all of the options have extremely low probability of being right, they still just pick whichever path has the highest probability.
So, for example, it has some idea of the places where a guitar might go in an image, and it could look for whatever part of the noise seems most like it could be the edge of the guitar (even though there really is no “right” choice), and starts filling things in.
Since there’s no right answer, every time you give it a different image of pure noise it’s going to come up with a different piece of artwork!
How Do You Program Stable Diffusion?
If I wasn’t familiar with machine learning, and I was trying to guess at how this is actually implemented, I’d probably start to think up how you would program it. In other words, what’s the sequence of steps it follows?
Maybe it matches keywords from the description to search a database of images that match the description, and then compares them to the noise? And from that guy’s explanation, it sounds like it might start by calculating where the strongest edges are in the image? 🤷♂️
The truth is nothing like that–it doesn’t have a database of images to reference, it doesn’t use any image processing algorithms… It’s pure math.
And I don’t mean that in the sense of “well, sure, computers are ultimately just big calculators, and everything they do boils down to math”. I’m talking about the “bewildering equations on a chalkboard” kind of math, like the ones below:

(That’s from a technical tutorial I wrote on one of the many building blocks of Stable Diffusion called “Attention”.)
The full set of equations that define each of the different building blocks would fill a few pages, at least.
Images and Text as Numbers
In order to apply these equations, we need to represent that initial noise image, and our text description, as big tables of numbers.
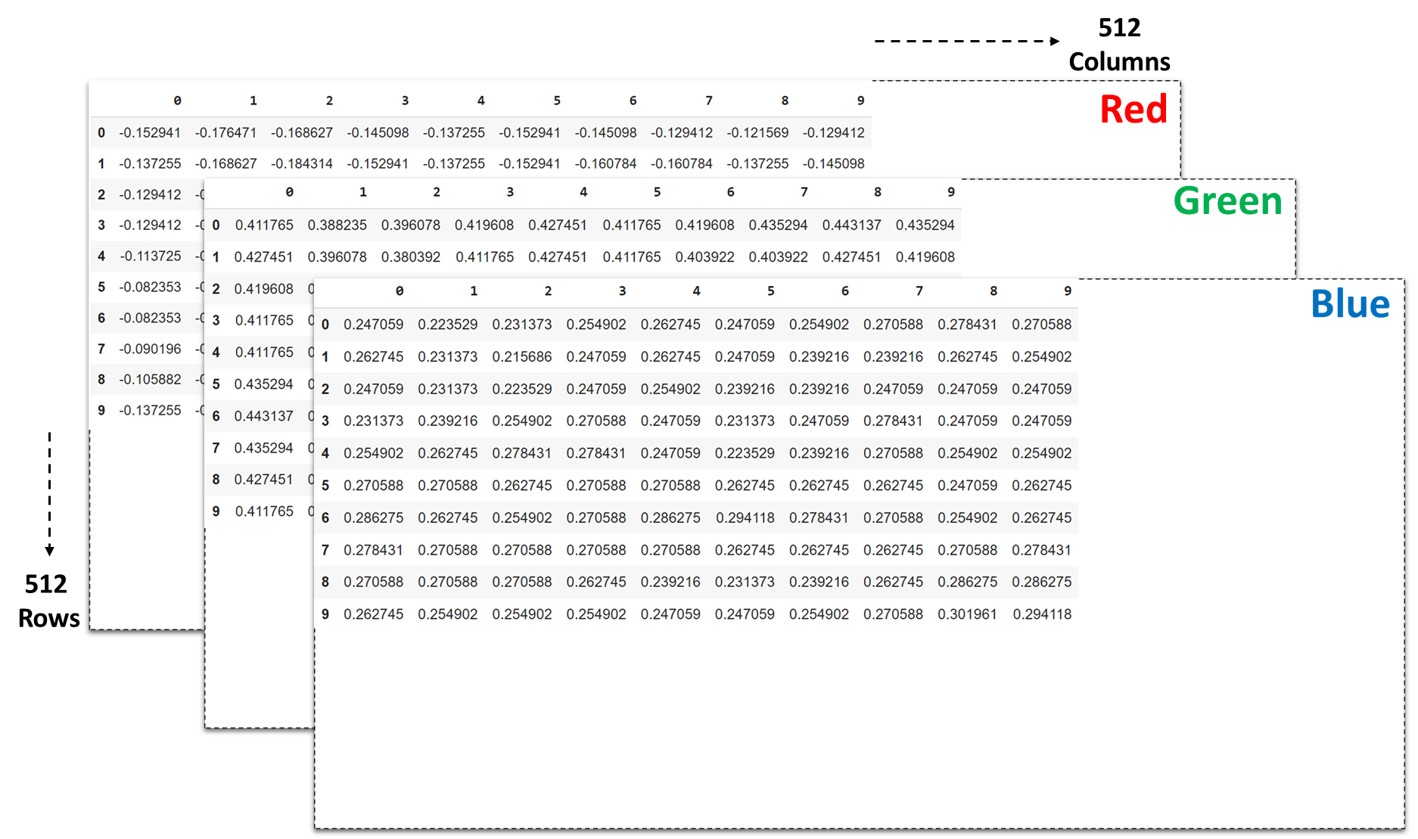
You might already be familiar with how images are represented, but let’s look at an example. Here’s a long exposure photo I took at high tide:

And here’s how it’s represented mathematically. It’s 512 x 512 pixels, so we represent it as a table with 512 rows and 512 columns. But we actually need three tables to represent an image, because each pixel is made up of a mixture of Red, Green, and Blue (RGB). Here are the actual values for the above image.
With Stable Diffusion, we also work with text. Here’s a description I might write for the image:
A long exposure color photograph of decaying concrete steps leading down into the ocean, with concrete railings, head on view, symmetry, dream like, atmospheric.
And here’s how this is represented as a table of numbers. There is one row for each of the words, and each word is represented by 768 numbers. These are the actual numbers used in Stable Diffusion v1.5 to represent these words:
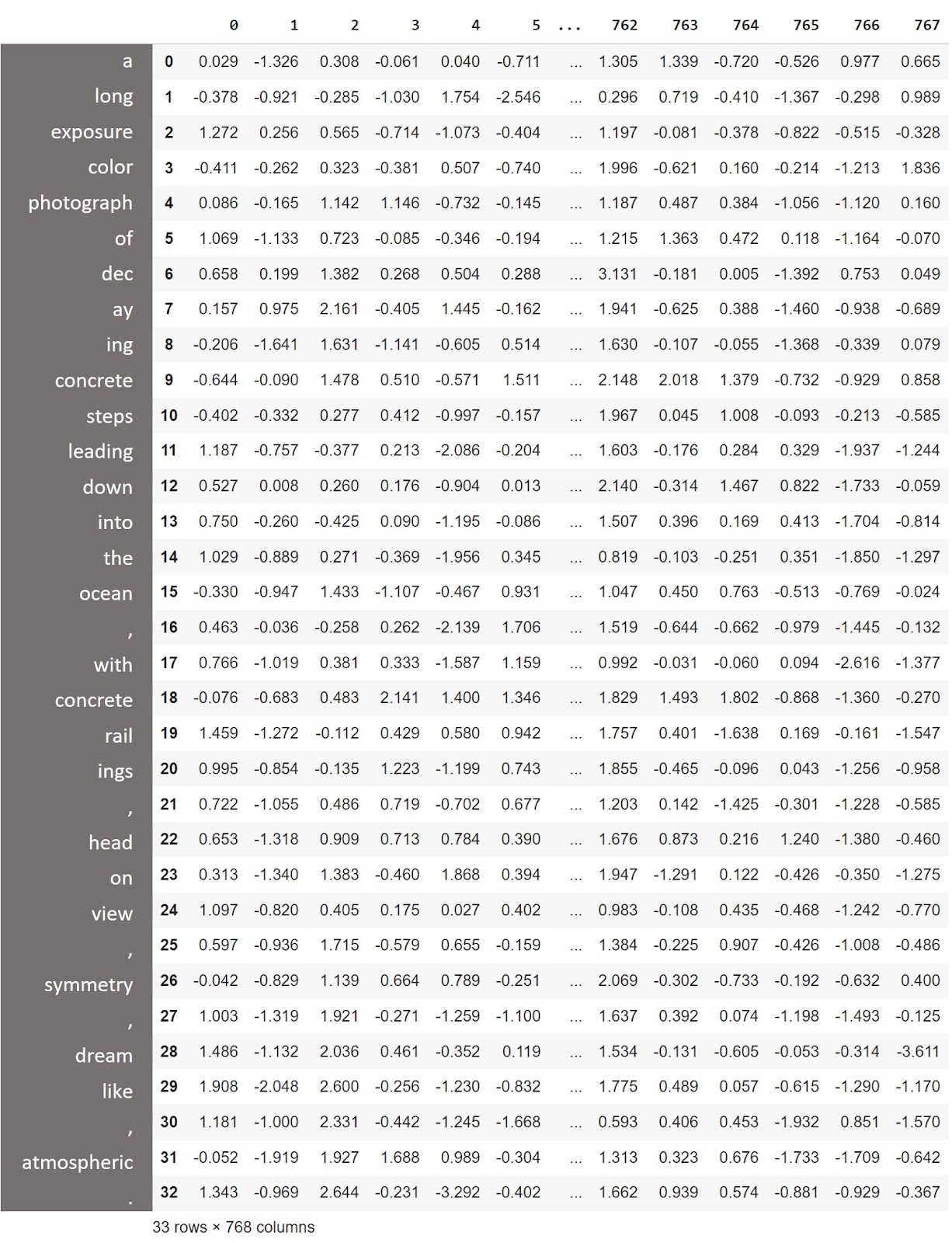
How we choose the numbers to represent a word is a fascinating topic, but also fairly technical. You can loosely think of those numbers as each representing a different aspect of the meaning of a word.
In machine learning, we don’t actually refer to these as “tables”–we use the terms “Matrix” or “Tensor”. These come from the field of linear algebra.
The most important and mind-bending part of all of this, though, is the concept of parameters.
A Billion Parameters
The initial noise and our text description are what we call our inputs to Stable Diffusion, and different inputs will have different values in those tables.
There is a much, much larger set of numbers that we plug into those equations as well, though, that are the same every time–these are called Stable Diffusion’s parameters.
Remember plotting lines in high school with equations like y = 3x + 2?

If this were Stable Diffusion, then ‘x’ is our input, ‘y’ is the final image, and the numbers 3 and 2 are our parameters. (And, of course, the equations are wildly more complex 😝).
The input image was represented by about 790k values, and the 33 “tokens” in our prompt are represented by about 25k values.
But there are roughly 1 billion parameters in Stable Diffusion. 🤯
(Can you imagine doing all of that math by hand?!?)
Those 1 billion numbers are spread out across about 1,100 different matrices of varying sizes. Each matrix is used at a different point in the math.
I’ve printed out the full list of these matrices here, if you’re curious!
Again, those parameters don’t change–they’re the same numbers every time you generate an image.
Stable Diffusion works because we figured out the right values to use for each of those 1 billion numbers. How absurd is that?!
Choosing 1 Billion Parameters
Obviously, the authors could not have sat down and decided what numbers to try. Especially when you consider that they’re not “integers” like 1,2,3, but rather what we computer nerds call “floating point” values–the small, very precise fractions that you saw in the tables.
Not only did we not choose these numbers–we can’t even explain a single one of them! This is why we can’t fully explain how Stable Diffusion works. We have some decent intuition about what those equations are doing, but a lot of what’s going on is hidden in the values of those numbers, and we can’t fully make sense of it.
Insane, right?
So how do we figure them out?
We start by picking 1 billion random numbers to use. With those initial random parameter values, the model is completely useless–it can’t do anything of value until we figure out better parameter values to use.
So we apply a mathematical process that we refer to as training which gradually adjusts the values to ones that work well.
The way training works is something we do understand fully–it’s some basic calculus (albeit applied to a very large equation) that’s essentially guaranteed to work, and we have a clear understanding of why.
Training involves a huge dataset of training examples. A single training example consists of an input and a desired output. (I’ll explain what a training example looks like for Stable Diffusion in another post).
When we run the very first training input through (with completely random parameter values) what the model spits out is going to be nothing like the desired output.
But, using the difference between the actual output and desired output, we can apply some very basic calculus on those equations that will tell us, for every one of those 1 billion numbers, a specific amount that we should add or subtract. (Each individual parameter is tweaked by a different, small amount!)
After we make those adjustments, the model is mathematically guaranteed to produce an image that’s a tiny bit closer to our desired output.
So we do that many times (hundreds of millions of times) with many different training examples, and the model keeps getting better and better. We get diminishing returns as we go, though, and we eventually reach a point where the model’s not going to benefit from further training.
Once the authors finished training the model, they published the parameter values for everyone to use freely!
Training Stable Diffusion
There’s a lot about the Stable Diffusion training process that’s easy to understand, and can be pretty interesting to learn, but I’m saving that for another blog post!
Conclusion
I won’t be offended if you’re a little disappointed by the explanation here, and that it’s not more understandable, but hopefully you at least feel like the veil has been lifted, and that what you saw was mind-bending and inspiring!