Optimizing Training with FlashAttention varlen
I’ve come to think of varlen primarily as the most efficient FlashAttention variant for training (it’s not used for generating tokens) because it handles our technique of “processing a batch of examples” more efficiently–by treating them as one long concatenated sequence, rather than adding an additional “batch dimension” to the input tensors, which handles varying sequence lengths less naturally.
Instead of running the transformer on a 2D matrix with shape (batch_size, max_seqlen), we use a 1D vector of length batch_size * max_seqlen, that can retain their original length–no padding required. (We still need to truncate too-long docs to max_seq_len, but otherwise they can be arbitrary).
I was able to reduce the nanochat d24 speedrun time by 1.8% by switching the code base over to varlen (I submitted a PR here). Karpathy had previously tested varlen, but I think was looking at it from the perspective of reducing cross-document noise rather than reducing flops.
In this tutorial, I’ll explain the varlen approach, its benefits, and how to implement it effectively.
Note: I’m coming at this from the perspective of a hyper-optimized, customizable training pipeline. Don’t expect a huge improvement from
varlen, and know that it may not be available if you’re relying on library code.
Contents
- Contents
- Standard Batch-Dim Approach
- varlen’s Performance
- Implementation
- Position Information
- Conclusion
Standard Batch-Dim Approach
With Padding
The simplest way to train on multiple samples at once is to put each one in its own row of the (batch_size, max_seqlen) matrix, and add padding tokens to fill out the unused positions.
For Encoder models we supply a padding mask to ensure that we’re not adding noise to the attention calculation from all of the meaningless pad tokens. For Decoders, it works to pad on the right without a mask, since tokens only attend to the left.
However, in both scenarios, we still pay the full compute cost as though they were all the same length (even when using a padding mask).
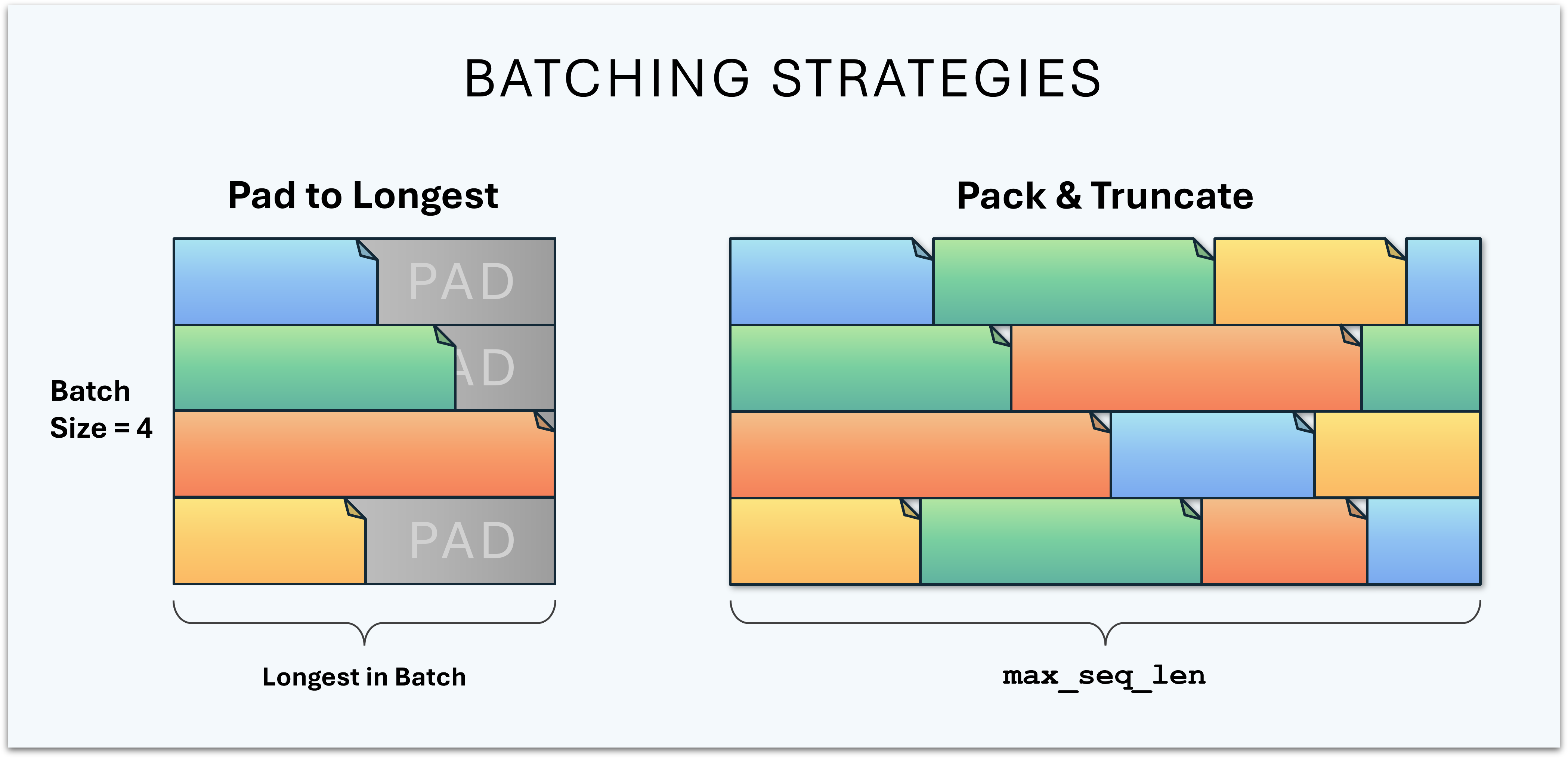
With Packing
To avoid wasting precious compute on pad tokens, we can pack the batch rows with multiple documents (truncating the final document in each row).
This has the consequence, though, of allowing the tokens to attend to tokens in unrelated documents, adding unhelpful noise to the attention step. Addressing this shortcoming seems to be the most common cited purpose of varlen.
Karpathy’s experiments on nanochat, however, suggest this may not be all that important of an issue in practice.
But there’s another crucial dimension to this–we’re still wasting compute calculating attention on irrelevant tokens!
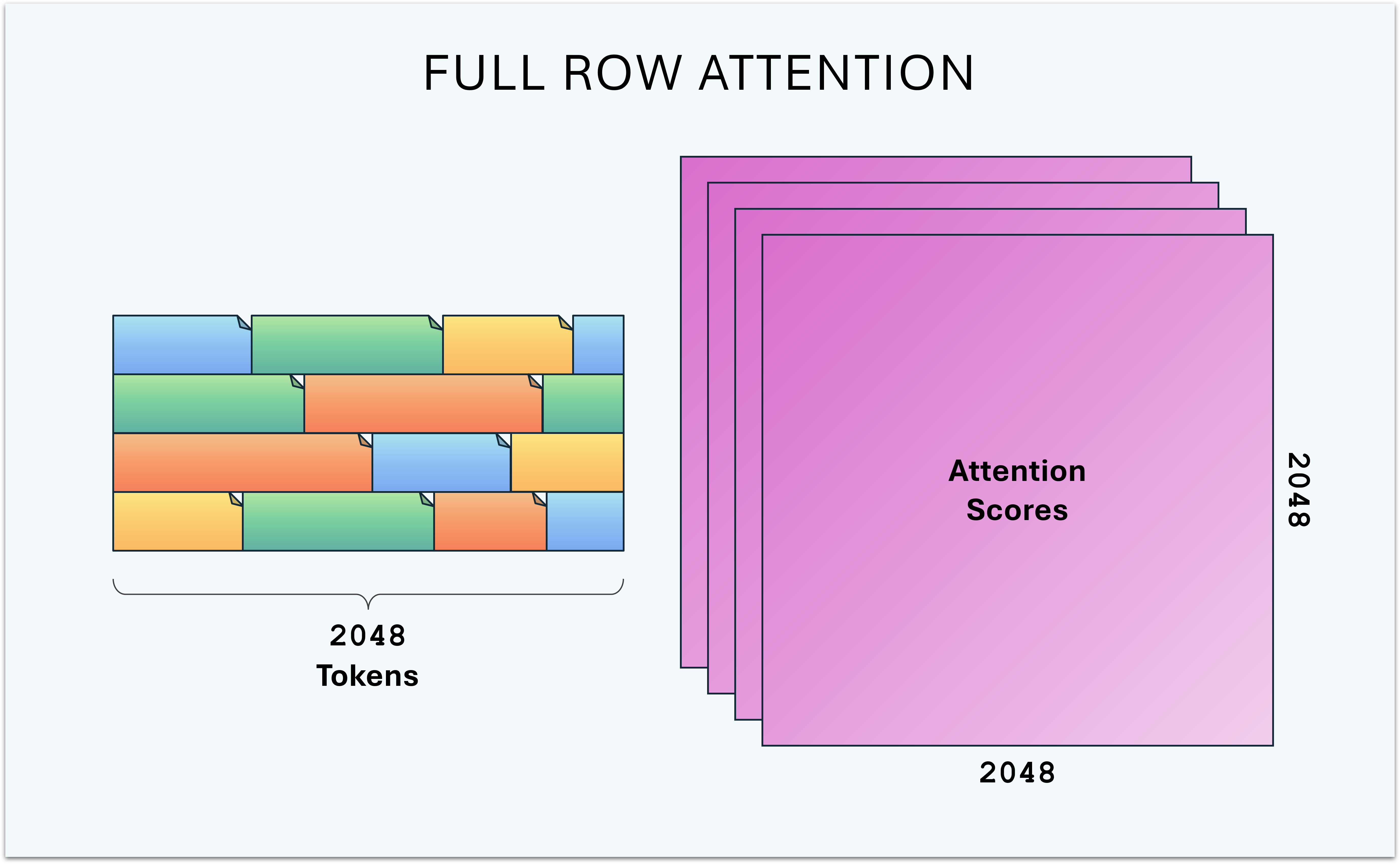
We’ve reclaimed a portion of the waste by including new tokens which can meaningfully attend to one another, providing additional training signal in the batch. But we’re still wasting flops on cross-document attention scores.
varlen’s Performance
varlen resolves both the “document bleed” and the wasted compute problem by only calculating attention within the documents.
FLOPs Comparison
Batch Dim Approach
Let’s use the actual dimensions from nanochat d24 to illustrate the comparison. It’s currently configured to train with a total batch size of 1M tokens, but this gets split up over 4 gradient accumulation steps and across 8 GPUs, so the actual batch matrices only contain 32K tokens each.
Note: I use the convention:
$M = 2^{20} = 1,048,576$
$K = 2^{10} = 1,024$
It makes the math a lot cleaner / easier!
The model’s maximum sequence length is 2K, so these 32K tokens are arranged as 16 rows of 2K tokens each.
For simplicity, I’ll ignore the number of attention heads, since that doesn’t affect the comparison.
This means attention will be calculated as a collection of matrix multiplications between 2K keys and 2K queries, which is 4M attention scores per batch row, and 64M attention scores for the whole 32K token batch.
varlen Approach
The FLOPs required by varlen depend entirely on the sequence lengths in the batch, but we can try some estimates.
Instead of 16 x 2K, we now have a flat 1 x 32K token buffer.
In the “worst case”, all of the documents are 2K tokens, and the FLOPs are the same.
In a more favorable case, let’s say it’s packed with 64 documents that all happen to be exactly 512 tokens in length (the fineweb dataset has a median length of about 400).
Note: Documents don’t need to be powers of 2 in length, I’m just using base 2 numbers for easier math.
In this case, we’ve packed 64 documents, so we’re doing 64 attention calculations
512 queries x 512 keys = 256K scores per document, and 64*256K = 8M scores total–8x fewer than batched attention.
In Practice
The actual performance benefit of varlen is much lower in practice, because:
- Those numbers assume full attention, but models like nanochat leverage windowed attention, which already reduces the number of calculations substantially.
- GPUs like big matrix multiplications, and the speedup from replacing a large matrix multiplication with multiple smaller ones tends to be much lower than the reduction in operation-count.
Implementation
Here’s how to implement varlen support and get the most from it.
- You’ll need classes that support it:
- A data loader which will pack correctly.
- A model implementation that includes it.
- It’s ideal to pick:
- A maximum number of documents to support per batch.
- A single maximum sequence length to train at.
- Leverage YaRN to avoid having to encode per-document positions.
Let’s break these down further.
Dataloader and API
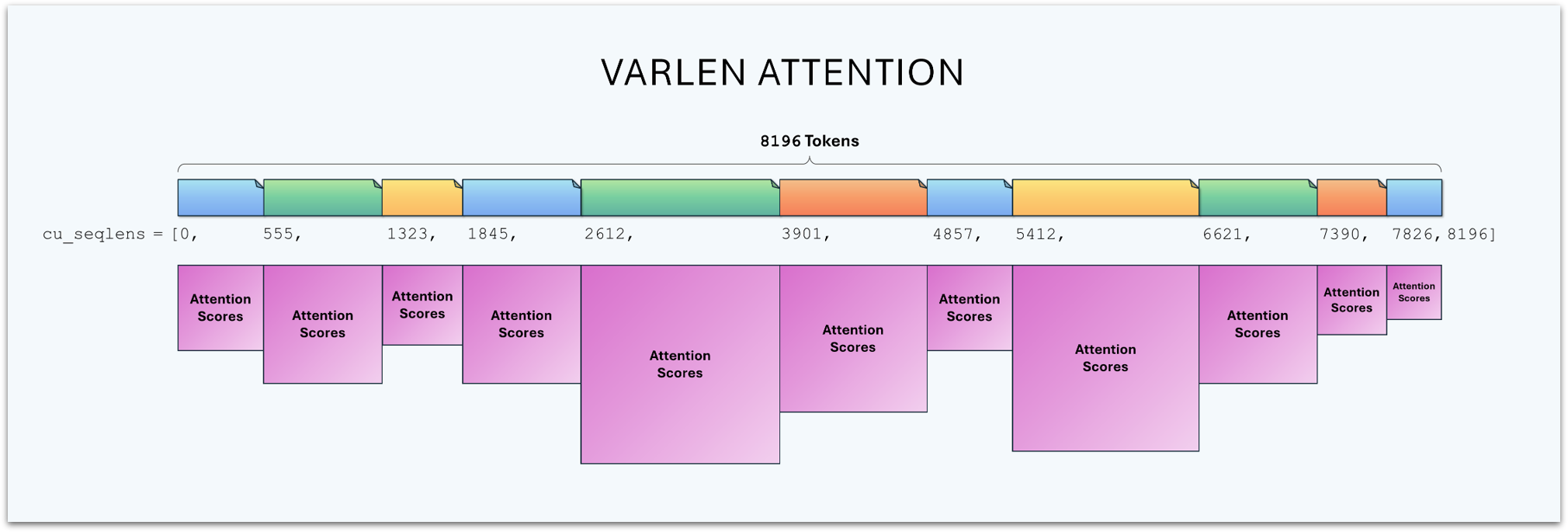
The main change required for supporting varlen, besides reshaping the input to a 1D buffer, is that we need to provide attention with an additional tensor containing the start index of each document.
This tensor is named cu_seqlens for “cumulative sequence lengths”. Kind of a strange naming choice. It comes from the fact that, given an array containing the length of each document, you can calculate the document offsets by accumulating the lengths.
It ultimately looks like:
[0, start_doc1, start_doc2, ..., total_tokens]
Note that cu_seqlens must always include the buffer length in its final position. i.e., it points to one past the end of the buffer.
If we have fewer than max_num_docs in the buffer, we fill the unused slots with that same position:
[0, start_doc1, ..., total_tokens, total_tokens, total_tokens]
The data loader needs to return the cu_seqlens tensor alongside the training batch, and the model’s forward function needs to take cu_seqlens and pass it down through each transformer block, looking something like:
def forward(self, x, targets=None, cu_seqlens=None):
# ...
for i, block in enumerate(self.transformer.h):
# ...
x = block(x, cos_sin, cu_seqlens, self.max_seq_len)
And into the attention block, which ultimately calls the varlen API:
y = flash_attn.flash_attn_varlen_func(
q, k, v, # Each of shape: (total_tokens, num_heads, model_dim)
cu_seqlens_q=cu_seqlens, cu_seqlens_k=cu_seqlens, # Document offsets
max_seqlen_q=max_seq_len, max_seqlen_k=max_seq_len, # Maximum document length
causal=True, # Tokens only look left.
window_size=window_size # Sliding context window size
)
Fixed Sizes for Compiling
torch.compile is incredible. When you look at the GPU traces for compiled vs. uncompiled model code, it’s hard to accept anything less.
Crucially, to achieve that glorious efficiency, you need to compile with fullgraph = True and dynamic = False.
model = torch.compile(model, fullgraph=True, dynamic=False)
Think of these flags primarily as a way of communicating the level of optimization you intend to achieve, so that compilation will fail if the conditions aren’t met, and you can go investigate.
fullgraph = True tells the compiler that you want to capture the entire forward and backward pass as a single graph. If the compiler encounters something it can’t execute without breaking the graph–like a Python print, or some data-dependent control flow–you’ll get an exception.
dynamic = False tells the compiler that you don’t intend to pass in any tensors which will vary arbitrarily in size. You can still pass in different sizes, but it will create a separate graph for each. That can be fine if you want to support 2 or 3 fixed shapes, but if you start passing in a variety of shapes it will quickly hit its “recompile limit” during training and throw an error.
These are the least flexible and most performant settings. When compiling fails, you should take this as an indicator that you need to go dig and find what’s getting in the way, because usually you can fix it by customizing the code for your specific needs.
Note: AI / coding agents will often try to remove those flags if there isn’t an easy way to resolve the problem while keeping the code general-purpose. You’ll need to clarify your willingness to tailor the code for your specific project.
How it Looks in varlen
The biggest challenge in compiling varlen is that the number of documents will vary from one batch to another, but the array for specifying their boundaries (the cu_seqlens tensor) needs to stay a fixed length.
max_num_docs
We can achieve this choosing a max_num_docs to support, and then unused positions in this array are pointed to just past the end of the buffer, i.e. to len(cu_seqlens) + 1.
# A batch size of 32K tokens with two unused document positions
cu_seqlens = [0, 500, 734, ..., 32768, 32768]
varlen will ignore these empty documents.
To choose max_num_docs, you’ll want to analyze the document lengths in your dataset, and then round up generously* to ensure you never have too few positions.
*Be less conservative, though, if you want maximum performance–more on that further down.
max_seq_len
Just as with standard batched inputs, we choose a fixed max_seq_len for the model and truncate documents to this length if needed.
A 2D batch tensor makes this limit more obvious, since the second dimension is set to max_seq_len.
In varlen, it’s possible to mistakenly place a too-long document in the buffer, and this will get you in trouble. FlashAttention won’t handle the tokens past max_seq_len, leaving garbage data that will crash your training run with NaNs.
This applies to the final document as well. If you use up your max_num_docs but haven’t fully filled the 1D buffer, the spare tokens at the end will ruin the gradients and kill the run.
Pathological Batches
To be robust against a rogue, pathological batch (e.g., full of many tiny documents), some ideas / options could be:
- Just discard the batch (sacrificing the data) and move on to the next one. Or,
- Compact the
cu_seqlensarray by (repeatedly) “merging” small documents to free up positions. You merge two docs by simply removing the offset of the second one fromcu_seqlens.- Note that this does result in some cross-document attention.
Aside: Maximizing Performance If you’re really trying to max out the performance (e.g., to eek out a speedrun record!), it turns out that overpadding
cu_seqlensis meaningfully harmful. I managed a modded-nanogpt record by simply trimmingmax_num_docsto better fit the actual training data, here. In the nanochat speedrun, at one point I hadmax_num_docs = 512, and this actually makes varlen slower than batched attention. My submission was withmax_num_docs = 96, chosen by analyzing all 270 shards of the training set (the actual max in the dataset, in its current order, is something like 81 docs).
Position Information
If we are packing documents into a vector, will we need to restart the position IDs at 0 at the start of each document?
Batched attention (with packing) faces the same issue. It turns out that restarting the position is unnecessary because of RoPE. RoPE is fundamentally relative–attention looks at the distance between tokens rather than their absolute position.
varlen adds another layer to this, though. We have a single long buffer, much longer than the model’s maximum sequence length. Doesn’t this mean we need some kind of context extension method (like YaRN) to handle position indices up to 32K?
It turns out we don’t, thanks to the combination of RoPE’s relativity and varlen’s attention boundaries. RoPE’s attention score between a query at position m and a key at position n depends only on (m - n), not on m or n individually. And since varlen restricts attention to within each document (at most 2K tokens), the relative distances that show up in the attention math are always small–regardless of where the document sits in the buffer.
As a concrete example, let’s say we have a 400 token document sitting at position 21,000 in the buffer. varlen will only include tokens inputs[21000:21399] in the attention math, and to the attention heads these produce exactly the same attention patterns as tokens at positions 0-399. The model literally cannot tell the difference.
So we just use plain RoPE and precompute enough positions to cover the full buffer–no extension method needed.
Conclusion
My takeaway from studying and working with varlen is that it’s simply the right answer to parallelizing work on variable length sequences.
If you’re fine with wasting significant compute on padding tokens, then a batch with one row per sample, padded to max_seq_len, is still the simplest and most intuitive approach.
If you’re planning on doing anything more clever than that, the only reason I can think of to continue using a batch dimension is if you’re using a library like HuggingFace which doesn’t support varlen well.
Otherwise, varlen seems to me like the most principled, intuitive, and efficient answer to processing multiple sequences. Unless I’m missing something, it seems like it deserves to become our new default understanding of how inputs are defined and shaped for training Transformer models.