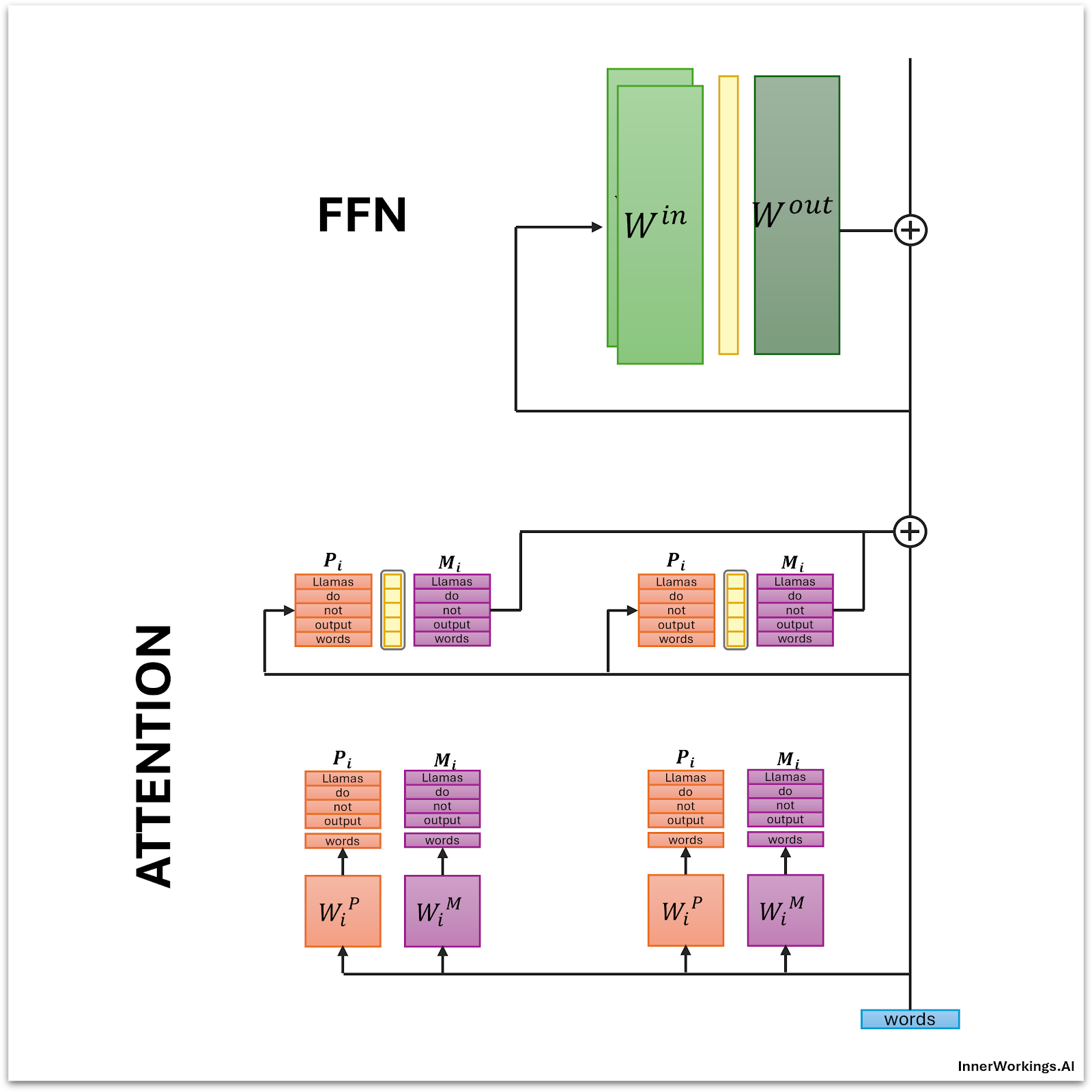
Something I find really helpful about this merged-matrix perspective is that it puts everything in “model space”. The patterns and messages and their projection matrices all have the same length as the word embeddings.
When you reduce Attention down to two matrices instead of four, the pattern and message vectors represent a more familiar architecture–they form a neural network, whose neurons are created dynamically at inference time from the tokens.
One potential benefit for this merged perspective is that it lets us begin our research into Transformer efficiency from a “more fundamental” definition of Attention.
In the previous post, we looked at how our tendency to think of Attention in terms of large matrix multiplications obscures some key insights, and we rolled back the GPU optimizations in order to reveal them (recapped in the next section).