QLoRA and 4-bit Quantization

An in-depth tutorial on the algorithm and paper, including a pseudo-implementation in Python.
An in-depth tutorial on the algorithm and paper, including a pseudo-implementation in Python.
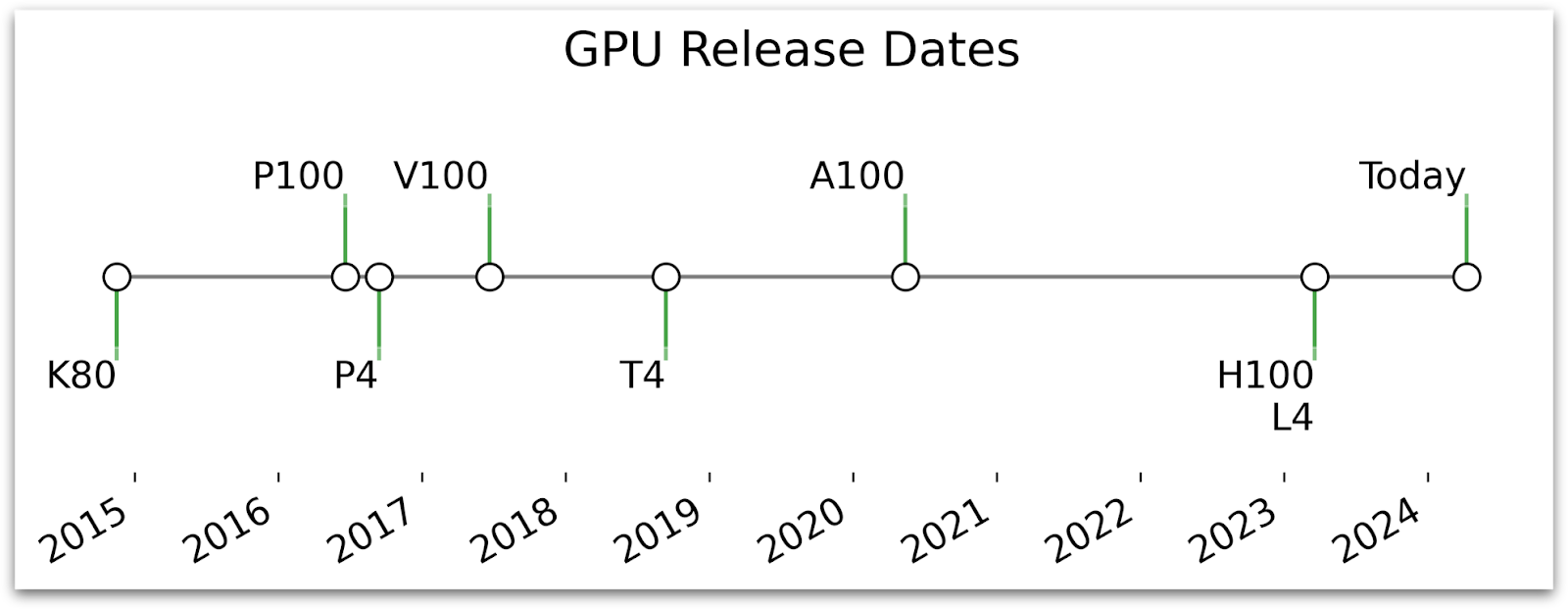
Updated March 2026
![]()

I’ve studied the samplers a bit and done some of my own experiments with them, and I’ve arrived at some tentative conclusions for what to do with them.

The Classifier-Free Guidance Scale, or “CFG Scale”, is a number (typically somewhere between 7.0 to 13.0) that’s described as controlling how much influence your input prompt has over the resulting generation.