The ability for a computer to generate art from nothing but a written description is fascinating! I know that I, for one, would be desperately curious to see what’s actually going on “under the hood” that would make this possible, so I wanted to do what I can here to provide a less superficial explanation of what’s going on even for those who aren’t familiar with the concepts in artificial intelligence.
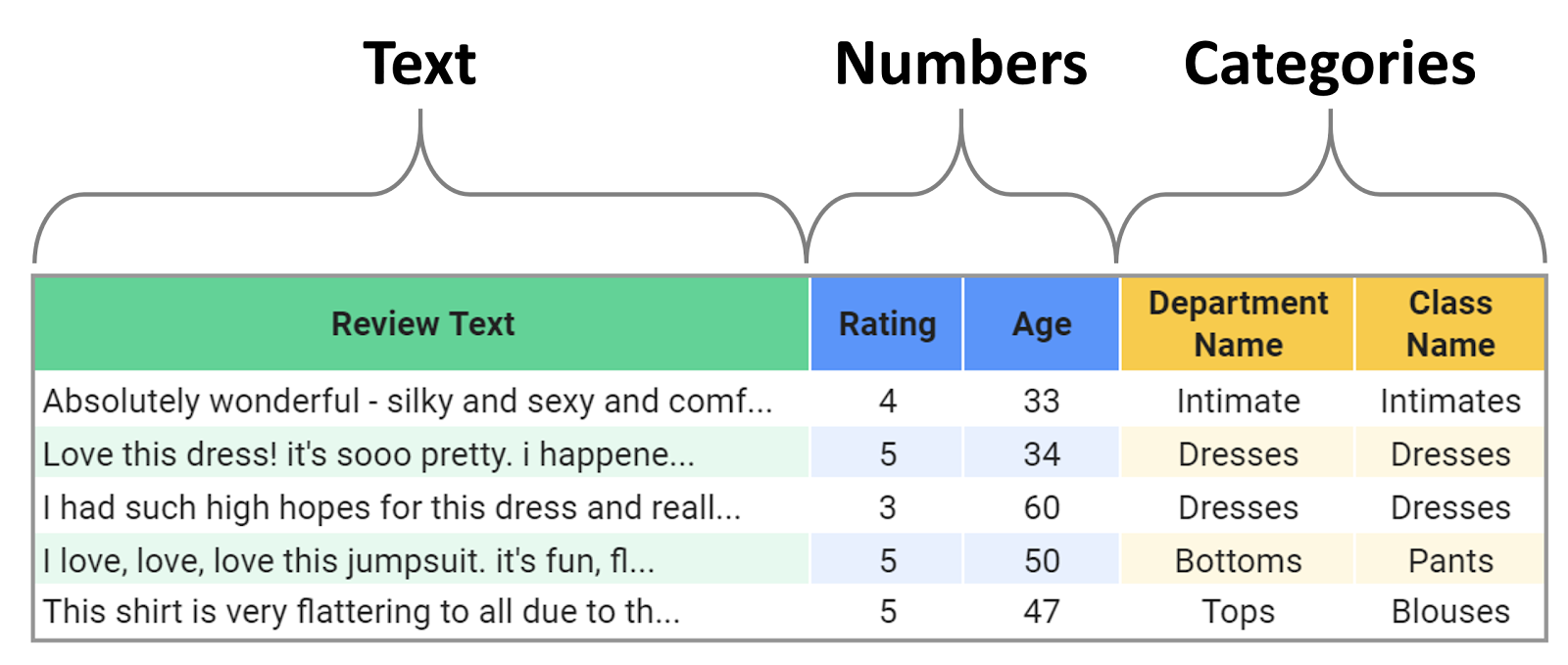
In this tutorial we’ll look at the topic of classifying text with BERT, but where we also have additional numerical or categorical features that we want to use to improve our predictions.
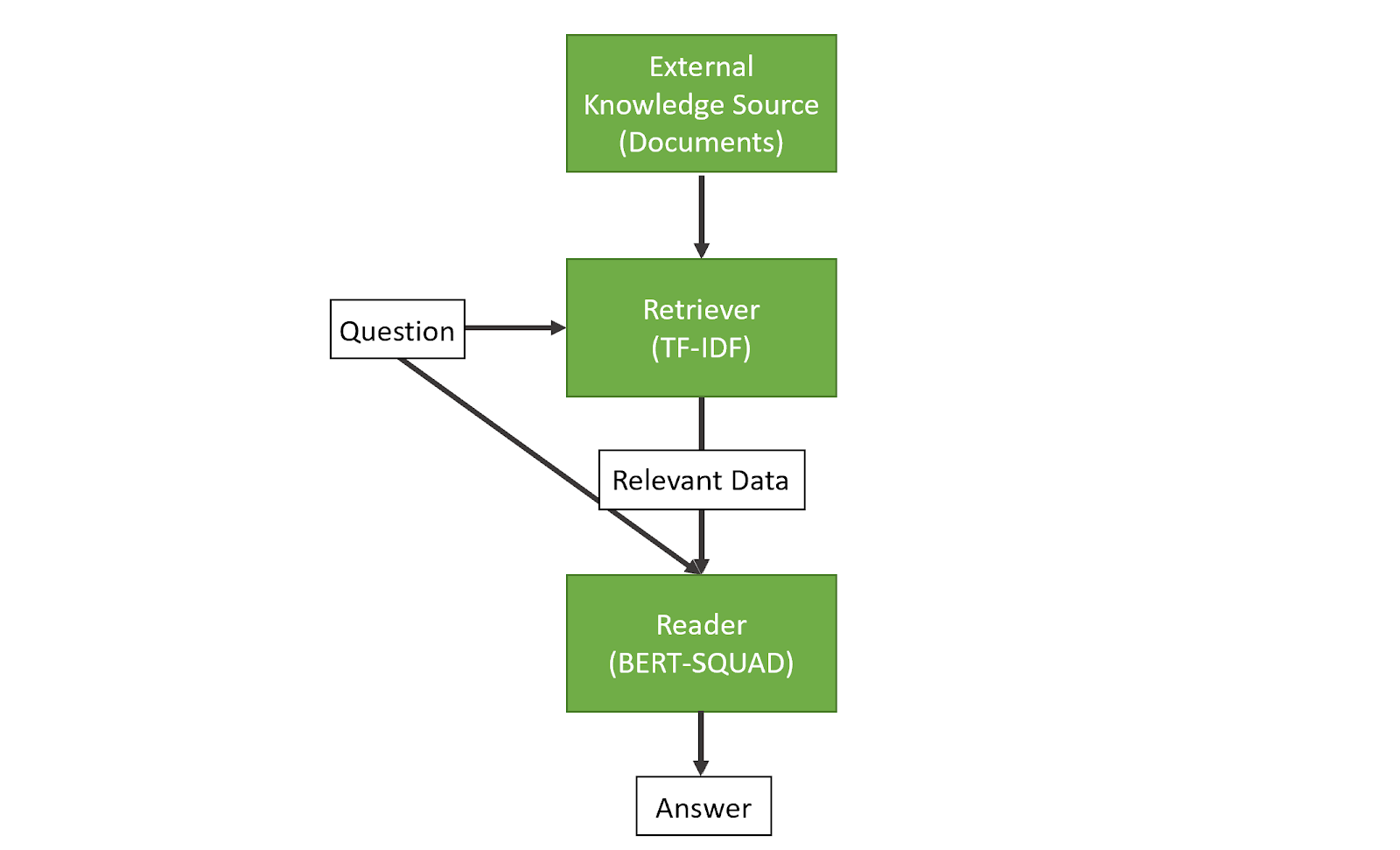
In this post, we’ll create a very simple question answering system that, given a natural language question, returns the most likely answers from a corpus of documents.