Recent models like DeepSeek-V3 and Moonshot’s Kimi-K2, built using Multihead Latent Attention (MLA), have shown that constraining the input spaces of attention heads can be both effective and efficient. They project the input token vector–size 7,168–down to just 512 dimensions for keys and values, and to 1,536 for queries. Despite this aggressive compression, performance holds up well enough to support these frontier-scale models.
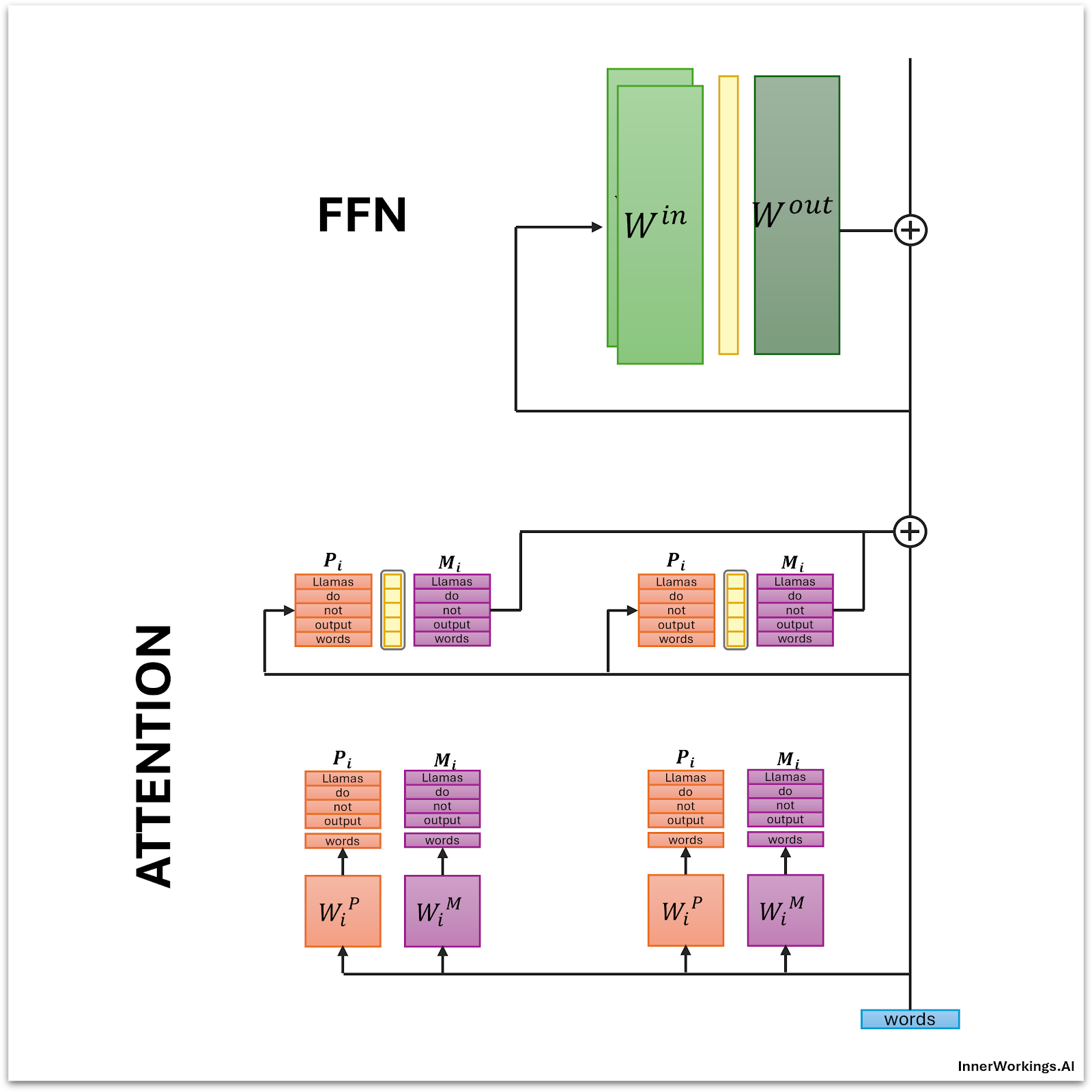
Multihead Latent Attention (MLA), introduced by DeepSeek in their V2 model, is an alternative to standard attention (and other variants such as MQA and GQA) which dramatically reduces memory bandwidth requirements for the attention calculations.
What had me most excited about the merged matrix perspective (and perhaps overly so) was that the patterns and messages are in model space, the same dimension as the vocabulary.
Something I find really helpful about this merged-matrix perspective is that it puts everything in “model space”. The patterns and messages and their projection matrices all have the same length as the word embeddings.