2020 NLP and NeurIPS Highlights
In this post I wanted to share some of the main themes from NLP over the past year, as well as a few interesting highlights from NeurIPS, the largest annual machine learning conference.
by Nick Ryan
Contents
Trends in NLP
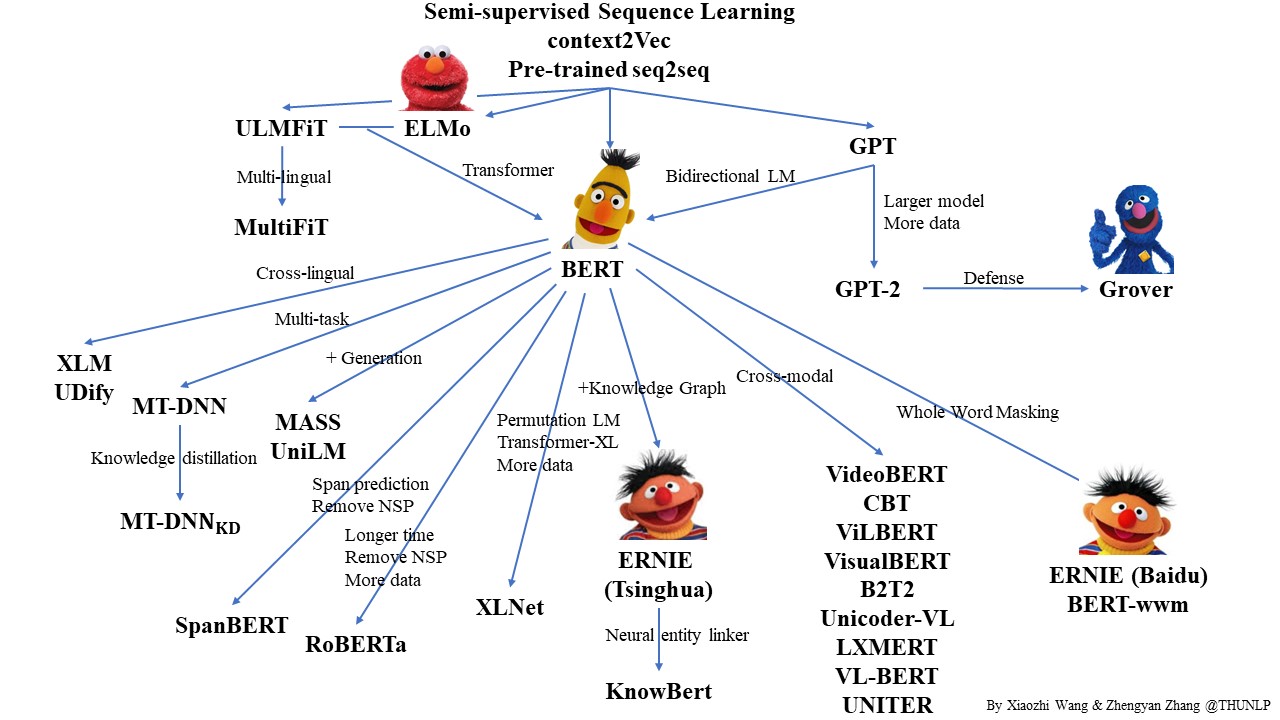
There was an explosion of new language models in 2020. The Huggingface transformers library now directly supports over 40 language model architectures, compared to 13 language models at the beginning of 2020. Besides minor improvements to benchmark scores, these language models demonstrate a creative variety of applications including tabular data understanding, cross-lingual understanding, style-controlled text generation, etc.
The variety and volume of language models came with a much improved understanding of their workings, strengths, and shortcomings. However, the remarkable increase in traditional benchmark task performance seen in 2018 and 2019 was not repeated. The current GLUE benchmark leader is only around 3 points higher than at the start of the year, though improvement in SuperGLUE did jump about 5 points and surpassed the human benchmark.
In addition to more language models came growing interest in a number of related NLP areas, including:
-
“BERTology” investigates the inner workings of large language models, how they represent different aspects of language within their layers/weights, and how alterations to the input and training regimen affects the model. This kind of analysis continues to provide insight into the strengths, weaknesses, and peculiarities of language models while also producing new ideas for their improvement. See here for a great overview.
-
Ethics and application of large language models to real-world applications. Models trained on large internet corpora are notorious for generating toxic language and usually contain biases that make them unfit for many applications. Until we have a good way to reliably fix these problems, bringing them into production remains unfeasible for many applications.
-
Multilingual language models and monolingual language models in a wide variety of different languages are now widely available (see the huggingface community models page). In addition, new datasets for non-English benchmarking such as XTREME, XQuaD, and XGLUE have made multilingual evaluation easier.
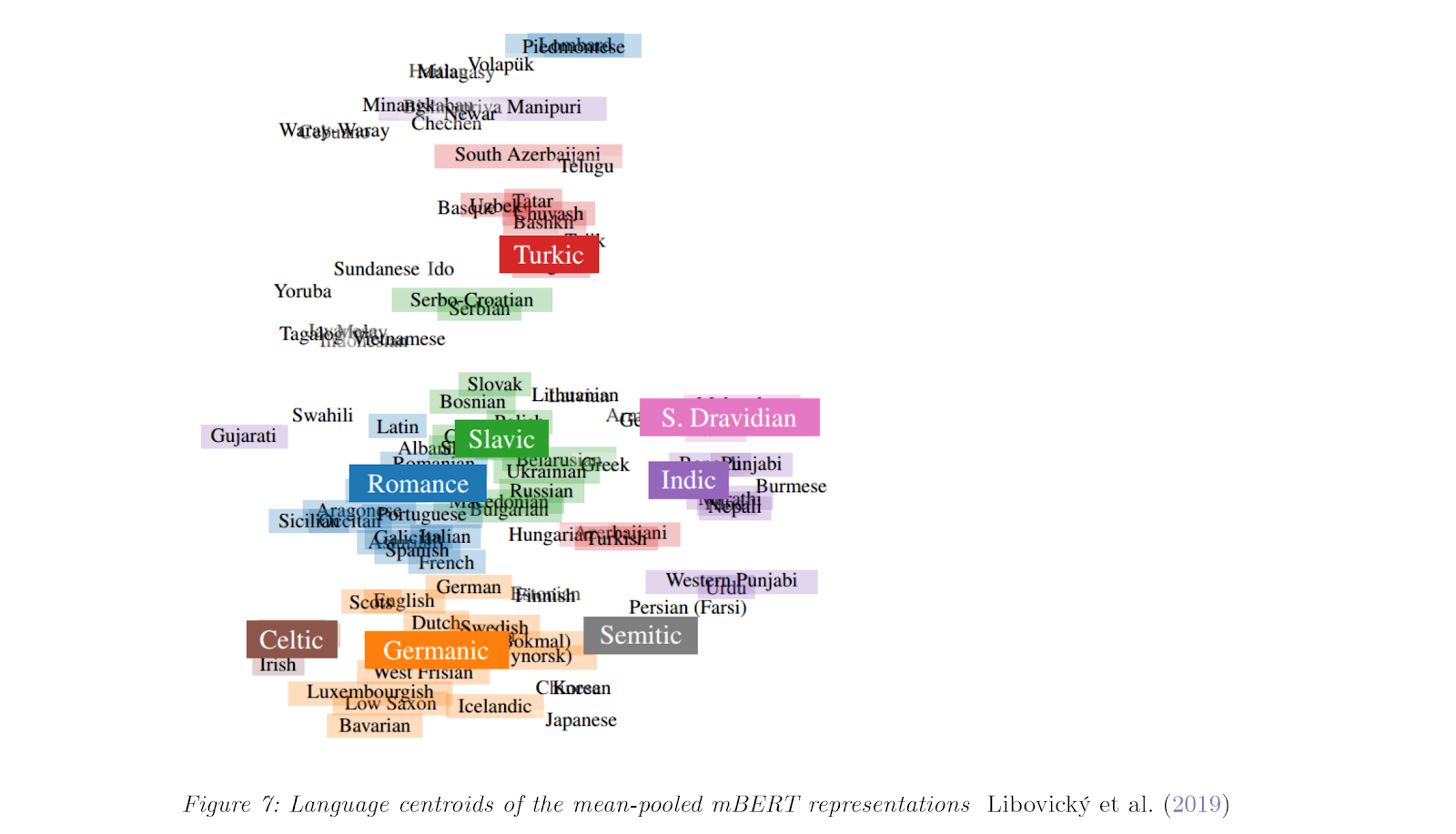
In the drive to produce more accurate natural language understanding, new models have attempted to squeeze out more performance on benchmark tasks with an enormous variety of approaches. Typical approaches include:
- Varying the Transformer architecture (e.g. BigBird attempts to solve long sequence length problems with a modified approach to self-attention whose compute requirement scales linearly with the sequence length rather than quadratically)
- Varying the training regimen and overall model architecture (e.g. DeBERTa, which holds the top position on the SuperGLUE benchmark task, represents each word in a sequence with not one but two separate vectors to encode content and position separately and uses these to compute attention weights in a novel way
- Increasing the size (e.g. GPT-3, which won best paper at NEURIPS 2020, has a whopping 175 billion parameters compared to T5, one of the next largest language models with a mere 11 billion parameters). While the large models like GPT-3, T5, or Meena have garnered lots of attention, researchers have also turned their attention towards making language models smaller and more efficient through pruning, quantization, distillation, and training regimen tricks to decrease training time.
NeurIPS
Many of the year’s most interesting ideas both in an outside of NLP were discussed at NeurIPS. Here are some highlights and talks that might interest you to check out the rest of the conference, much of which has been made available to the public for free at this time.
NLP
EfficientQA Competition

(System designers presenting in Efficient QA Competition: Computer Systems)
In this competition sponsored by Google and judged/presented at NeurIPS, participants were challenged to create the best possible open domain question answering system that is asked a series of natural language questions covering a broad range of topics and must answer, without consulting the internet, in natural language. The questions (from a dataset called Natural Questions) are google search questions from real users. Participants are allowed to use any dataset, but all questions are answerable using Wikipedia so this was preferred for nearly all submissions. The catch is that the systems (including code, knowledge corpus, and model parameters) are constrained in size, forcing researchers to make their systems efficient, rather than merely large and complex. The competition was split into four tracks:
- Unlimited system size
- System must be under 6GiB
- System must be under 500MiB
- The smallest system to achieve 25% accuracy
In recent years we have seen that simply increasing the number of parameters in a model reliably increases model performance. By adding size constraints to the competition objectives, the competition pushes researchers to further investigate the cost-benefit of different architecture and compression choices, and provide insights for real-world applications that can’t always accommodate enormous language models. Here are some takeaways from the write-up applicable to NLP and language models in general:
- The final accuracy between the unrestricted track and the 6 GiB track was negligible. The authors speculate that perhaps this small gap is specific to the nature of the Natural Questions task, where questions are answerable by a small subset of Wikipedia reference articles. However, models like GPT-3 and T5 tested on the Natural Questions task underperformed the winners in the 6 GiB track significantly indicating that, at least for now, task-specific fine-tuned systems still hold a significant advantage against massive language models like GPT-3 for many tasks. -Relying on knowledge retrieved from an external corpus performed better than only relying on the “knowledge” that is stored within a language model’s parameters. While this is again specific to the Natural Questions dataset, the authors found the advantage of retrieval-based systems unsurprising.
- Greatly reducing the size of the Wikipedia 20 million article reference corpus via article filtering, product quantization, and reducing initial vector sizes generated from the dataset resulted in only a minimal loss of performance. One of the top submissions in the 6GiB track reduced the Wikipedia corpus from 60GiB of vectors down to 1.2GiB
- Ambiguity plays a large role in figuring out how to effectively evaluate question answering systems. This is inherent to language tasks and is not necessarily a fault of the systems. A good deal of the competition evaluation was about getting human evaluators to agree and defining categories to denote the ambiguity of the questions and probable correctness of the answers. For example (from the paper): “the question “who has the most superbowl rings”’ could be read as “which person (including coaches) has the most superbowl rings”’, “which player has the most superbowl rings”, “which team has the most superbowl rings”. All three [human] annotators identified this question as being ambiguous but they disagreed about the validity of the different readings.“
- Learning to make progress in this domain by improving evaluation metrics, curating questions, or designing more holistic systems that work with users to reduce vagueness (e.g. through asking clarifying questions) seems to be an important direction. Some questions won’t necessarily have one correct, unambiguous answer, so designing systems that can get humans the information they want in a more ensembled or holistic fashion seems like an interesting avenue, particularly for conversational AI.
Chatbot Tutorial
This tutorial led by Fung and her colleagues at Hong Kong University presented some state of the art approaches for creating chatbots. The talk does a great job of providing a framework to help break down into fine-grained detail the goals and difficulties within a domain as large and varied as chatbot agents that are asked to perform tasks, answer knowledge, chitchat with users, empathize, etc. A great overview of a topic that we’ll be covering in an upcoming post - stay tuned!
Bias and Ethics

The machine learning community is increasingly stepping up by calling on itself and others to pay more attention to the biases in their models and the ethics of applying these models in real world applications.
Isbell gave a very entertaining and creative (see the slide above) keynote presentation arguing why biases can exist at all levels of machine learning models (from application all the way down to dataset and loss function) and why it is the responsibility of the engineers and researchers to both understand and mitigate bias across the entire pipeline.
In addition to Isbell and the many other talks on fairness, the conference itself required all authors to outline the ethical aspect of their submitted work in the call for papers:
“In order to provide a balanced perspective, authors are required to include a statement of the potential broader impact of their work, including its ethical aspects and future societal consequences. Authors should take care to discuss both positive and negative outcomes.”
New Directions
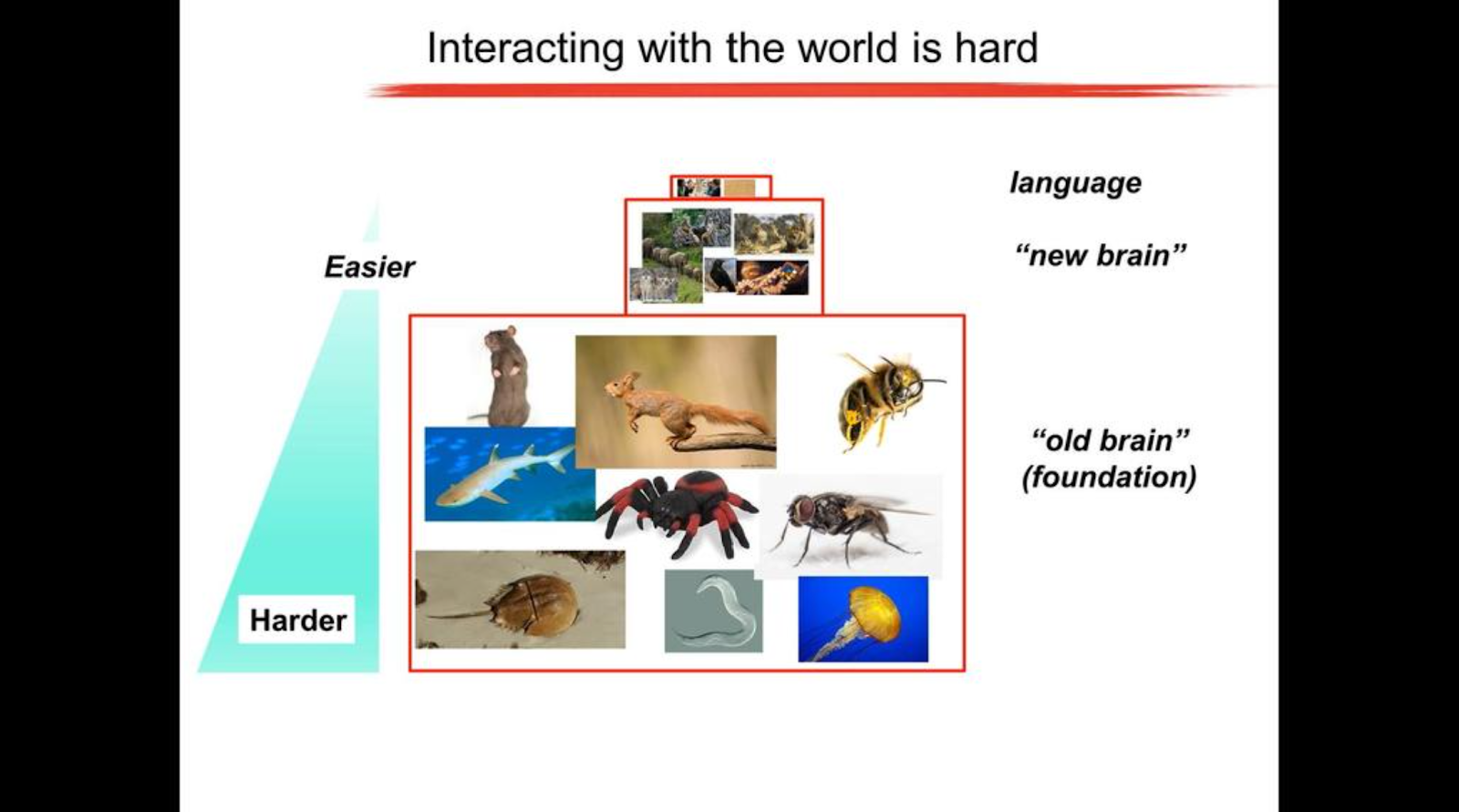
(From Zador’s The Genomic Bottleneck: A Lesson from Biology)
The conference included a number of more abstract discussions about the future direction of AI, mostly revolving around whether or not deep learning is sufficient to create more advanced AI or whether something else needed. Many talks used insights from neuroscience and biology to inform new approaches.
Below are some of the more interesting talks discussing a few of these ideas.
Zador points out that features of human intelligence like language and reasoning evolved only recently as small layers on top of an enormous amount of innate sensorimotor “old brain” capability - capability to explore and interact with the world developed in animals over hundreds of millions of years. Zador argues that instead of trying to learn these high level functions we should first build the much more difficult structural foundation of the old brain upon which the high level functions can then be added.
Wang and her colleagues at DeepMind discuss the parallels between neuroscience and AI, in particular how reinforcement learning might be instantiated in the brain and where AI research can take (and has taken) inspiration from neurobiology.
Chollet argues that creating systems that can generalize broadly across novel domains is the key to making progress in AI. Chollet defines generalization as split into two kinds of abstractions. One type of abstraction takes place over a continuous space where one can sensibly interpolate between lots of different examples. For example, deep learning systems can create a generalized “prototype” of a face after seeing many different images of faces because these images exist in a continuous high-dimensional space. Deep learning models are good at interpolating between examples that are close together in this space to “create” a manifold that all images of a face, roughly, should fit on. Chollet argues that deep learning works if and only if the problem can be interpreted on a continuous space and you have plenty of data points.
The other type of abstraction takes place in a discrete domain. It is therefore not suitable for deep learning and requires a different approach that can, at a high level, identify isomorphisms and merge them into abstract types. That’s hard to conceptualize but might look like, for example, a software engineer who notices that a single kind of method is used redundantly across multiple different functions. She decides to abstract that method into its own higher-level function and replace the different redundant blocks of code with a call to the new higher-level function. That kind of abstract reasoning over different discrete forms is categorically different from the kinds of problems that deep learning tackles, and Chollet argues that deep learning is not able to represent this problem in a meaningful way.
This framework provides a compelling distinction between those aspects of intelligence that deep learning excels at and struggles with, and provides a concrete reason for this distinction that suggests new directions that do not rely on deep learning.

Chollet has created a dataset, ARC, intended to measure general human-like intelligence that deep learning systems specifically struggle with. The task presents sequences of colorful patterns arranged on grids and asks the system to create the logical continuation of the patterns.
We have seen again and again that new research proposals, particularly about how to accelerate research towards AGI, are often extremely compelling but difficult to evaluate tangibly, contextualize, or demonstrate the practical ability of. As such, from a research and learning perspective, it’s difficult to invest time into learning about something that has yet to demonstrate results: the proof is in the pudding. Chollet’s concrete benchmark task is a welcome way to keep track of substantive progress in this vein, and will give concrete evidence for his theory if a model that excels at ARC demonstrates good the properties of good, generalizable performance towards other related tasks.