Word2Vec Resources

While researching Word2Vec, I came across a lot of different resources of varying usefullness, so I thought I’d share my collection of links and notes on what they contain.
While researching Word2Vec, I came across a lot of different resources of varying usefullness, so I thought I’d share my collection of links and notes on what they contain.
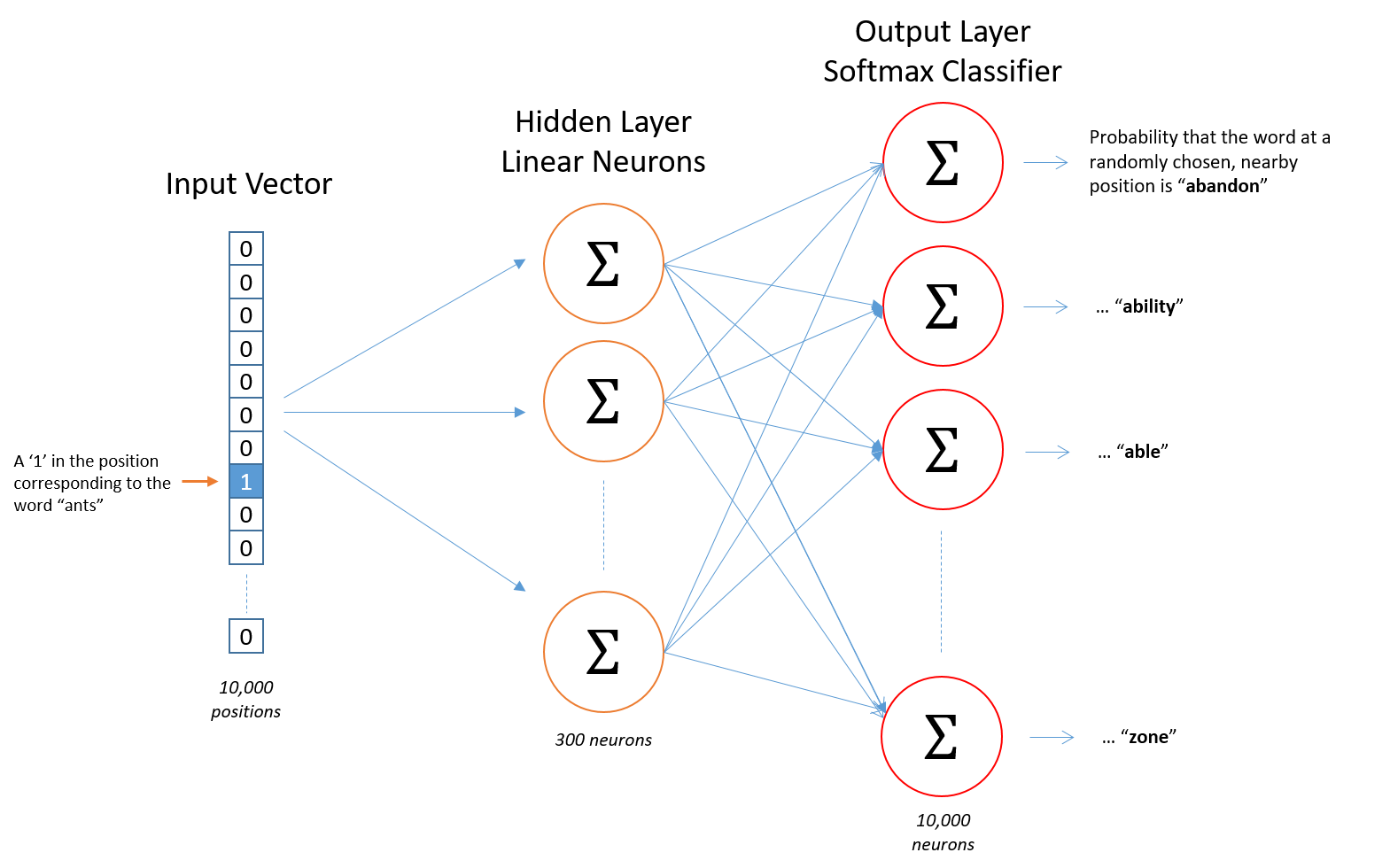
This tutorial covers the skip gram neural network architecture for Word2Vec. My intention with this tutorial was to skip over the usual introductory and abstract insights about Word2Vec, and get into more of the details. Specifically here I’m diving into the skip gram neural network model.
In this post I’m going to describe how to get Google’s pre-trained Word2Vec model up and running in Python to play with.
Nvidia puts on its GPU Technology Conference (GTC) each year to highlight work being done on GPUs outside of graphics–including machine learning.